1. 협업필터링
'추천시스템' 카테고리에 개념에 관한 설명이 있습니다.
2. 선호 정보 수집
예시로 쓸 데이터를 만듭니다.
- 영화 비평과 영화 평가 정보를 담은 딕셔너리
- 각각의 사람들이 영화에 대한 평점을 매긴 데이터입니다.
critics={"Lisa Rose":{'Lady in the Water':2.5, 'Snakes on a Plane':3.5, 'Just My Luck':3.0, 'Superman Returns':3.5, 'You, Me and Dupree':2.5,'The Night Listener':3.0},
"Gene Seymour":{'Lady in the Water':3.0, 'Snakes on a Plane':3.5, 'Just My Luck':1.5, 'Superman Returns':5.0, 'The Night Listener':3.0, 'You, Me and Dupree':3.5},
"Michael Phillips":{'Lady in the Water':2.5, 'Snakes on a Plane':3.0, 'Superman Returns':3.5, 'The Night Listener':4.0},
"Claudia Puig":{'Snakes on a Plane':3.5, 'Just My Luck':3.0, 'The Night Listener':4.5, 'Superman Returns':4.0, 'You, Me and Dupree':2.5},
"Mick LaSalle":{'Lady in the Water':3.0, 'Snakes on a Plane':4.0, 'Just My Luck':2.0, 'Superman Returns':3.0, 'The Night Listener':3.0,'You, My and Dupree':2.0},
"Jack Matthews":{'Lady in the Water':3.0, 'Snakes on a Plane':4.0, 'The Night Listener':3.0, 'Superman Returns':5.0, 'You, Me and Dupree':3.5},
"Toby":{'Snakes on a Plane':4.5, 'You, Me and Dupree':1.0, 'Superman Returns':4.0}}
알고리즘을 실험하거나 예시하는데 딕셔너리를 사용하면 편리하다. 검색과 수정이 모두 쉽기 때문이다. 메모리 안에 어느 정도 저장하지만 데이터가 커지면 데이터베이스 안에 저장할 수 도 있다.
3. 유사 사용자 찾기
* 각각의 사람을 다른 모든 사람들과 비교해서 similarity score를 계산해준다. 유클리디안 거리, 피어슨 상관계수는 실습을 통해 알아본다.
유클리디안 점수: 간단한 계산 방법이다. 예컨데 Toby와 LaSalle가 매긴 Snakes와 Dupree의 평점을 통해 두 사람 간의 유사도를 측정해본다.
우선 거리를 구하게 되면, 다음과 같다.
from math import sqrt
sqrt(pow(5-4,2) + pow(2-1,2))
이를 점수로 0~1 사이의 값으로 만들어 주기위해 1을 더하여 역수를 취해 준다. 거리가 짧을 수록 유사도 점수는 커지고 거리가 멀수록 유사도 점수는 작아진다.
1/(1+sqrt(pow(5-4,2) + pow(2-1,2)))
유클리디안 거리 점수를 출력해주는 함수
# person1과 person2의 거리 기반 유사도 점수 리턴 함수
def sim_distance(prefs, person1, person2):
# 공통항목추출
si={}
a=list(prefs[person1].keys())
b=list(prefs[person2].keys())
c=set.intersection(set(a),set(b))
both = list(c)
if len(c)==0: return 0
#공통항목에 대해서만 유클리디안 거리 점수를 구함.
x = []
for i in both:
x.append(pow((prefs[person1][i]-prefs[person2][i]),2))
return 1/(1+sqrt(sum(x)))
함수 사용 결과
sim_distance(critics, "Mick LaSalle","Lisa Rose")
피어슨 상관 점수
피어슨 상관계수는 두 개의 데이터 집합이 한 직선으로 얼마나 잘 표현되는지를 나타내는 측정값이다. 유클리디안 보단 복잡하지만 잘 정규화되지 않은 데이터의 경우에 훨씬 나은 결과를 제공한다. 예컨데 평론가들의 영화평점은 일반적으로 평균보다 더 엄격하기 때문에 이럴 때 피어슨 상관점수가 더 적합하다고 할 수 있다.
코드를 통해서 두 사람 사이의 피어슨 상관점수를 통한 유사도를 계산해본다. 유클리디안 처럼 식이 직관적이지는 않지만, 변수들이 각각 변화하는 정도들의 곱으로 함께 변하는 정도를 나눈 것을 알려준다.
아래에는 각 변수들의 평균 필요없이 요소들을 가지고서 상관계수를 구할 수 있는 변형된 공식이다. 상관계수를 구할 때 아래의 식대로 구할 것이다.

# person1과 person2의 피어슨 상관점수
def sim_pearson(prefs, person1, person2):
# 공통항목추출
si={}
a=list(prefs[person1].keys())
b=list(prefs[person2].keys())
c=set.intersection(set(a),set(b))
both = list(c)
if len(c)==0: return 0
#요소들의 개수를 구함
n=len(both)
#모든 선호도를 합산
sum1=sum([prefs[person1][i] for i in both])
sum2=sum([prefs[person2][i] for i in both])
#제곱의 합을 계산
sum1Sq = sum([pow(prefs[person1][i],2) for i in both])
sum2Sq = sum([pow(prefs[person2][i],2) for i in both])
#곱의 합을 계산
pSum = sum([prefs[person1][i]*prefs[person2][i] for i in both])
#피어슨 상관 점수 계산
num=pSum-(sum1*sum2/n)
den=sqrt((sum1Sq-pow(sum1,2)/n)*(sum2Sq-pow(sum2,2)/n))
if den==0: return 0
r=num/den
return r
함수 실행 결과
sim_pearson(critics, "Mick LaSalle","Lisa Rose")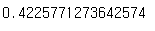
유클리디안과 비교했을 때 큰 차이는 없고, 다만 피어슨 상관점수가 약간 더 낮게 나온 것을 알 수 있다.
자카드 계수, 맨해튼 거리와 같은 유사도를 측정하는 다른 방법도 있으나, 여기선 다루지 않는다.
평론가 순위
두 사람을 비교하는 함수를 만들었다, 이제 주어진 사람을 기준으로 다른 모든 사람들과의 점수를 계산하여 가장 근접한 상대편을 찾는 함수를 만들어 본다. 가장 유사한 성향을 가진 사람은 누구인가를 판단할 수 있게 된다.
def topMatches(prefs, person, n=5, similarity=sim_distance):
#앞서 만든 함수를 활용하여 다른 모든사람들과의 유사도를 구함.
scores=[(similarity(prefs,person,other),other) for other in prefs if other!= person]
#최고점이 상단에 오도록 목록을 정렬
scores.sort()
scores.reverse()
return scores[0:n]
함수실행결과
topMatches(critics,"Lisa Rose",n=3)
결과를 통해서 해당 사람과 가장 유사한 사람을 찾아볼 수 있었다. 이를 활용한다면 나와 유사한 평론가는 누구인지 찾고 그 평론가의 평론을 읽어보는 것도 재밌을 것이다.
'Programming_Collective Intelligence > 2.추천시스템 만들기' 카테고리의 다른 글
| 무비렌즈(MovieLens) 데이터 셋을 활용한 추천 시스템 (0) | 2019.12.29 |
|---|---|
| 항목 기반 필터링/추천 생성 (0) | 2019.12.29 |
| 제품 매칭 (0) | 2019.12.28 |
| 항목추천/제품매칭 (0) | 2019.12.26 |




댓글