추출요약(Extractive Summarization)은 문서에서 가장 중요하다고 판단되는 k 개의 문장을 순서대로 나열하여 요약합니다.
BERT(Bidirectional Encoder Representation using Transformer)는 MLM과 NSP로 학습한 임베딩 모델
기존 BERT의 경우 Masked Language Modeling 으로 단어에 대한 representation을 산출하며, Nest Sentence Prediction 방법으로 두 개의 문장을 입력받도록 구성된 모델입니다. 그리고 오픈된 시중의 BERT류의 모델은 positional Embeddings의 max size는 512로 고정되어 있습니다.
BertSum은 Input Document 라인에서 input값을 입력 받으면 Token, Segment, Position Embeddings를 거쳐 summation 하게 됩니다. 이 후 해당 벡터는 bidirectional Transformer layers에 임베딩으로써 들어감으로써 각 token의 contextual vector를 생성해냅니다. BERT와는 다르게 [CLS]를 여러개 집어 넣어 다수의 문장 representations를 학습하고, 한 문서 내의 문장들을 구별하기 위해 interval segmentation embeddings(BertSum아키텍처 Segment Embeddings 부분의 빨간/초록 부분)를 사용합니다. interval segmentation embeddings에서 $E_{A}$와 $E_{B}$가 문장 순서대로 홀짝으로 반복되어 사용됩니다. 이로써 문장의 구조를 이용해 문서의 표현을 학습할 수 있다고 합니다.
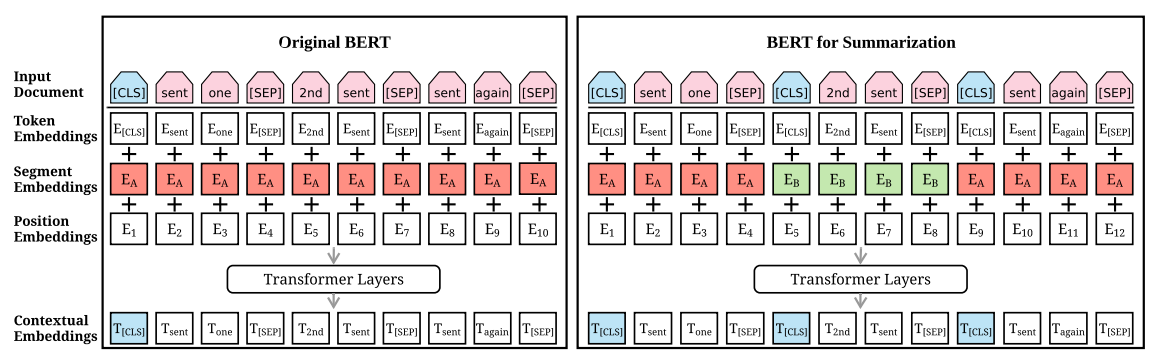
각 sentence를 의미하는 $sent_{i}$는 $E_{A}$, $E_{B}$를 거쳐 최종적으로 $T_{i}$ 벡터로 산출되고 $i$번째 sentence의 [CLS]의 벡터라고 할 수 있습니다.

문장 $sent_{i}$는 마지막으로 $\hat{Y}_{i}$로써 0 또는 1로 예측값을 산출합니다. 이는 해당 sentence가 요약문에 포함이 될 수 있는지 없는지를 나타내는 예측값으로 Sigmoid function을 거쳐 0~1 사이의 값을 가지며 이를 활용해 sentence의 중요도 순위를 매길 수 있게 됩니다.
BertSum 논문에서는 $\hat{Y}_{i}$을 산출하는데 MLP(Multi Layer Perceptron), Transformer, RNN을 사용한 실험 결과를 보여줍니다. 이 중 MLP를 활용한 Simple Classifier를 다음과 같이 정의합니다.
$\hat{Y}_{i} = \sigma (W_{o}T_{i} + b_{o})$
input 값에 대해 문장별로 CLS토큰을 넣어주어 문장 간의 관계를 학습할 수 있도록 해주고, down stream task로써 분류 모델을 학습해 문장별 이진분류를 통해 해당 문장이 input에 대해 각각 요약문으로 사용될 수 있는지를 판단하게 해주는데요. input 값의 max값이 512정도로 다소 size가 크다는 생각이 들지만 CLS토큰으로 데이터를 셋팅해주고, Interval Segment Embeddings에서 문장별로 $E_{A}$, $E_{B}$를 오고가며 셋팅해준 후, 배치 단위가 하나의 input이므로 하나의 뉴스가 들어갔을 때, 각 문장들에 대한 요약값이 나오게 Summarization Layers를 셋팅해주는 부분들에 대한 소스 코드 수정이 핵심적이라 생각합니다.
다소 오래전에 나온 방법론이긴 하지만 문서의 주요 문장을 추출해내는 태스크에 맞춰 모델을 튜닝한 것이 인상 깊었습니다. 이밖에 BERT, GPT모델을 보완한 KOBART모델이나 또는 ELECTRA모델로도 문서의 주요 문장을 추출해 요약하는 방법이 있으니 직접 구현해 사용할 일이 있다면 해당 모델로 더 나은 성능의 모델을 만드는 것이 좋을 것 같다는 생각이 듭니다.
ref)
Fine-tune BERT for Extractive Summarization
Text Summarization with Pretrained Encoders
https://github.com/nlpyang/PreSumm
https://github.com/uoneway/KoBertSum
https://kubig-2021-2.tistory.com/53
'NLP' 카테고리의 다른 글
| reading LangChain docs (2) (0) | 2024.01.17 |
|---|---|
| reading LangChain docs (1) (0) | 2024.01.16 |
| 트위터 데이터 수집 (a.k.a twitterscraper) (0) | 2020.02.05 |
| 비정형 데이터 - Doc2Vec (0) | 2019.12.19 |
| 비정형 데이터 - LDA (0) | 2019.12.16 |



댓글