DevOps 철학인 자동화의 계보를 잇는 MLOps. 자동화하지 않으면 고장난 것이다라는 말에 동의하나요? 저는 동의합니다. 한번 만들어 놓은 분류 모델이 영원히 제 성능을 발휘하리라 믿는 사람은 없을 거라 생각합니다. 일반화 성능에서 정확도 100%를 달성할 수 없는 것은 현실세계의 문제는 1차원적이지 않기 때문입니다. 이는 곧 모델이 스스로 뚝딱뚝딱 보완하고 업그레이드를 하면 좋겠다라는 니즈가 발생합니다.
그래서! 현재 기준으로 내가 만들 수 있는 가장 훌륭한 모델을 만들었다면 앞으로 발생할 새로운 케이스들을 입력으로 받아 나이스한 추론 결과를 보여주겠죠. 데이터사이언티스트로 일하다보면 나이스한 추론 결과를 내도록 모델을 정교화하는 것도 물론 중요하지만 더 중요한 것은 역시 비즈니스에 잘 녹아들게 하느냐라고 생각하는 요즘입니다. 시스템적으로 말이죠. 애초에 비즈니스 시스템에 엇박자로 맞춰져 있다면 아무리 좋은 모델이라 한들 무용지물이 될테니까요.
주니어로 일하면서 준실시간, 배치단위의 API 서빙으로 결과를 받아볼 수 있게 구축해본 경험이 있는데, 뭐 가슴에 손을 얹고 생각하면 참 많이 부족하죠. 그리고 정말 뼈저리게 느끼고 있는 것은 지금 내가 개발한 모델이 A/B 테스트에 적용되기까지 그리고 나아가 실제 서비스에 적용되기까지 백엔드, 데이터엔지니어 등 연관부서 개발자들에게 너무 의존적이다라는 것입니다. 의존적이다라고 표현한 것은 내가 공부하면 좀 더 빨리 서비스 할 수 있는데 그렇지 못하기 때문입니다. 또 피드백이 느리다보면 자연스레 모델들의 최신화 유지도 느려지고 업데이트가 느려지면 품질이 떨어진채 오래 방치된다는 것이니 전체적으로 아쉽죠.
그래서 ML 프로젝트의 전체적적인 아웃라인을 체험해보고, 겪어보면서 내가 현업에서 좀 더 영향력을 행사할 수 있는 부분은 어느부분인지. 나의 현상태는 어떻게 프로젝트 내부에서 좀 더 나은 퍼포먼스로 타부서와의 협업에서 나은 서포팅을 할 지 알아보기 위해 도서를 선택하여 공부하기로 했습니다. 책은 오렐리에서 나온 MLOPs 실전가이드라는 책이고 현재 기준으로 볼 때 최신입니다. 👍 중간에 막히는 부분도 있을 것이고 우선은 정독과 구현을 목표로 기록해볼 참입니다! 웰컴첨언!
주요 키워드
- 지속적통합(Continueous Integration): 코드 병합 후, 소프트웨어, 코드의 품질을 지속적으로 테스트하고, 테스트를 기반으로 소프트웨어의 품질을 향상시키는 프로세스를 말한다.
- 지속적배포(Continue Deployment): 코드형 인프라를 사용해 코드를 자동으로 스테이징 환경 또는 프로덕션 환경에 배포하는 프로세스를 의미한다.
- 마이크로서비스: 의존성이 거의 없고, 독립적인 기능을 가진 소프트웨어 서비스를 의미한다. 내가 혼자 Flask 등을 활용해 추론 API서버를 띄워놓은 것과 같은 것을 의미한다.
- 코드형 인프라(Infrastructure as Code): 인프라를 소스 코드의 형태로 보관하고 배포하는 프로세스를 의미한다.
구현파트
먼저 기본적인 DevOps를 구현해본다. 벌써 두렵다. 하지만 전진해본다.
CI는 데브옵스에서 핵심요소 둘 중 하나인데, 파이썬 프로젝트의 경우에는 CI가 비교적 수월한 편이라고 한다.(아싸) 테스트 자동화의 첫번째 단계는 스캐폴드(scaffold)를 구성한다.
스캐폴드는 어떤 아웃라인. 틀. 이라고 생각하면 된다. 예시는 아래와 같다. 다음과 같은 구조를 채택하면 ML프로젝트 구현이 수월해진다.
1. Makefile
2. requirements.txt
3. hello.py
4. test_hello.py
그럼 우선 Makefile은 무엇일까? 메이크파일은 유닉스 기반 운영체제와 함께 제공되는 메이크 시스템을 통해 파일에 작성된 명령을 실행하는 파일이다. 궁극적으로 매번 기억하기 어렵고 복잡한 빌드 단계를 관리할 때 복잡성을 줄여준다. 환경을 빌드하기 위한 환경들을 기록해두기 때문이다. 도커 이미지를 만드는 Dockfile 파일이랑 비슷할지도?
그렇기에 도커에서 pip 설치하는 것처럼 make install 로 설치를 할 수 있고, make lint로 코드의 구문오류 확인, make test로 소스코드를 테스트해볼 수도 있다. 도커 이미지를 만들고 컨테이너를 실행해본 경험이 있다면 명령어를 지정해서 해당 명령을 실행하도록 지정한다는 것을 알 수 있다. 코드들은 페이지 맨 아래의 저자의 깃헙 소스코드를 활용했다.
install:
pip install --upgrade pip &&\
pip install -r requirements.txt
install-gcp:
pip install --upgrade pip &&\
pip install -r requirements-gcp.txt
install-aws:
pip install --upgrade pip &&\
pip install -r requirements-aws.txt
install-amazon-linux:
pip install --upgrade pip &&\
pip install -r amazon-linux.txt
lint:
pylint --disable=R,C hello.py
format:
black *.py
test:
python -m pytest -vv --cov=hello test_hello.py>> 1. Makefile
requirements.txt는 파이썬 패키지 설치 기본 도구인 pip에서 사용하는 규약이다. 설치할 패키지에 대한 버전등의 정보를 담고 있다. 도커 이미지를 만들 때도 사용했던 파일과 이름이 똑같다.
pytest
click
pylint
pytest-cov>> 2. requirements.txt
hello.py는 우리가 실행하고자 하는 소스파일이며, 스캐폴딩에는 테스트파일 test_hello.py도 포함된다. 아래의 두 코드를 보면 테스트의 역할을 알 수 있다. 테스트 파일은 임포트를 위해 같은 경로에 있어야한다.
def add(x, y):
"""This is an add function"""
return x + y
print(add(1, 1))>> 3. hello.py
from hello import add
def test_add():
assert 2 == add(1,1)>> 4. test_hello.py
스캐폴드가 뭔지 개념이 와닿았다면 CI를 해보기 위해 파이썬 가상환경을 생성보자. 아래의 코드를 통해 가상환경 활성화까지 진행해본다.
python3 -m venv ~/.your-repo-name #가상환경 생성하기
source ~/.your-repo-name/bin/activate #가상환경 활성화
이제 Makefile의 install 명령어를 실행해서 지정된 명령어를 실행하도록 해보자. 아래와 같이 간단한 명령어라 곧장 바로 실행되고 pip를 설치하고 업그레이드 하고, requirements.txt의 패키지들을 설치하는 것을 알 수 있다.

이번엔 make lint를 싱행해서 린트를 적용해보자. 10점 만점의 10점을 얻었다. 나이스. 그냥 아무것도 안했는데 백점맞은 기분.

이어서 make test로 소스코드의 테스트를 거쳐본다. PASSED. 커버리지 100%. 미스없고.. 결과는 굿.

이게 기초다. 이 기초적인 틀을 잡고 프로세스가 성공하면 해당 프로세스를 원격 SaaS(Software AS a Service) 빌드 서버와 통합하는 것은 어렵지 않다. 대표적으로 깃허브 액션, AWS 코드빌드, GCP클라우드빌드, Azure DevOps 파이프라인, 젠킨스(써봤음) 등이 있다.
깃허브 액션을 사용하여 지속적 통합 구성하기.
CI를 한번 해보니 자신감이 생겼다. 이어서 원격 소스코드 저장소인 깃허브로 넘어가보자. 깃헙 액션은 CI를 빠르게 적용해볼 수 있는 가장 간단한 도구다.
내가 작업한 공간의 로컬 경로와 원격저장소 깃헙을 연결해준다.
그리고 나서 위의 스캐폴드 4개의 파일을 푸시해준 후에 로컬경로에 .github/workflows/<name>.yml 를 만들어 준다 yml파일은 기존에 오픈소스를 참조했다.
name: Azure Python 3.8
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v1
with:
python-version: 3.8
- name: Install dependencies
run: |
make install
- name: Lint
run: |
make lint
- name: Test
run: |
make test> 실행하려는 애플리케이션 이름을 name: 으로 지어준다.
> on: 은 해당 워크플로우가 실행될 트리거를 설정한다. 여기서 push는 git push를 하면 실행되는 조건이다.
> jobs: 는 해당 워크플로우에서 실행될 작업들이다.
> build: 는 실행될 작업중 빌드를 하겠다는 의미로 build라고 지정해준 것이다 <build>.
> runs-on: 은 OS환경을 지정한다.
> steps: 는 작업의 실행단계를 의미한다.
> users: actions/checkout@v2 는 깃헙 레포를 현재 경로에 체크아웃한다.
> name: Set up Python 3.8 작업은 파이썬 3.8을 설치한다,. actions/setup-python@v1을 활용해 파이썬 버전을 설정한다.
> name: Install dependencies는 앞에서 배웠던 make install 명령을 실행해서 프로젝트에 필요한 라이브러리와 패키지를 설치한다.
> name: Lint 는 make lint 명령을 실행해서 코드 리팩터링, 스타일 가이드 준수를 확인하는 작업을 수행한다.
> name: Test는 make test 명령을 실행해서 코드가 잘 작동하는지 테스트를 수행한다.
이제 로컬환경에서 git push를 하면 실제로 깃헙에 들어가서 Actions 버튼을 클릭해서 빌드가 되는 과정을 엿볼 수 있다.

>> 빌드에 실패하면 에러메세지를 확인해서 디버깅해준다. 책에 나온대로 진행하면 오래된 파이썬 버전 3.5 때문에?인지.. 아무튼 3.8로 바꿔서 해주니 아래처럼 빌드가 잘됐다.

>> 빌드 성공.
이로써 지속적통합을 테스트 해봤다. 이어서는 특정 위치에 코드를 배포하기 위해 지속적 배포 프로세스와 코드형 인프라를 사용한다.
배포는 클라우드에 펼쳐진 마스터, 스테이지, 프로덕션에 배포가 점진적으로 배포가 될 것이다. 스테이지의 경우에는 부하 테스트를 거치고, 마스터에서 최종확인해서 프로덕션 서버로 최종 배포되서 서비스가 될 것이다.
이제 DevOps의 지속적 통합에 이어서 DataOps를 수행하는 데이터 엔지니어링의 특징을 간략히 알아보면 다음과 같다.
- 데이터의 흐름이 자동화되어야 안정적인 MLOps를 수행할 수 있다.
- DataOps는 아파치 에어플로우와 같은 워크플로 예약, 관리, 모니터링 도구가 있다. 이밖에 AWS에서도 Glue, Athena, QuickSight 같은 DataOps 관련 플랫폼을 제공힌다.
- 데이터의 크기, 변경빈도, 품질 및 정제수준을 고려해 알맞은 저장소와 제품을 선택하는 것이 중요하다.
- 많은 회사에서 중앙 집중식 저장소인 데이터 레이크를 모든 활동의 허브로 사용한다. 내구성, 가용성 뿐만 아니라 무한에 가까운 확장성을 제공하기 때문이다.
AWS의 S3가 이에 해당한다. 나도 S3를 통해 이런저런 데이터를 많이 가져오고 또 이곳에 쌓아달라고 부탁도 하곤 한다. - 데이터 엔지니어의 작업은 아래와 같이 구성된다. 역시나 많은 업무를 담당하게 된다. 이중에서 데이터 사이언티스트는 가장 아래의 머신러닝 엔지니어링 작업을 위한 데이터 및 모델 버전 관리를 서포트하면 좋을 듯 하다.
- 주기적인 데이터 수집, 스케줄링 작업 실행
- 스트리밍 데이터 처리
- 서버리스와 이벤트 기반 데이터 처리
- 빅데이터 관련 작업
- 머신러닝 엔지니어링 작업을 위한 데이터 및 모델 버전 관리
플랫폼 자동화는 현재 사용하는 클라우드 기반 데이터 레이크의 회사에 맞게 설정하면 좋다. S3를 사용하고 있다면 SageMaker를 사용한다던지 GCP를 사용하고 있다면 vertexai와 같은 플랫폼을 사용하면 된다. 운영 복잡성을 줄이기 위해 이러한 하이레벨의 플랫폼을 사용하는 것도 좋은 방법이 될 수 있다! 돈이 많이 들겠지만!
데브옵스, 데이터 자동화, 플랫폼 자동화까지 모두 구축해야 MLOps를 다룰 자격이 생긴다. 다시 한번 명심할 것. DevOps방법론을 사용하여 머신러닝을 자동화하는 프로세스가 MLOps라는 것! 명심하자.
문제
1. 깃헙 액션을 사용해 두 개 이상의 파이썬 버전에 대해 깃헙 프로젝트 테스트를 수행하자.
name: Azure Python 3.8 and 3.9
on: [push]
jobs:
build_python_3_8:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.8
uses: actions/setup-python@v1
with:
python-version: 3.8
- name: Install dependencies
run: |
make install
- name: Lint
run: |
make lint
- name: Test
run: |
make test
build_python_3_9:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python 3.9
uses: actions/setup-python@v1
with:
python-version: 3.9
- name: Install dependencies
run: |
make install
- name: Lint
run: |
make lint
- name: Test
run: |
make test>> 단순히 파이썬 버전만 3.9인 것을 추가하는 코드를 작성했다. 주의할 점은 jobs하에 들어가는 이름은 알파벳, -, _ 만 사용할 수 있음에 주의하자.
2. 클라우드 네이티브 빌드 서버 중 AWS Code Build를 이용하여 CI를 수행해보자.
먼저 AWS에 가입하고 로그인을 해준다. 우선 루트사용자와 IAM 사용자가 나뉘는데, 루트사용자는 리눅스 환경에서 sudo 관리자나 마찬가지로 절대권한을 갖는다. 그래서 위험하니까 필요한 권한만 부여받아 작업할 수 있도록 하는 IAM 사용자가 등장한다. 보안, 권한 관리에 있어서는 IAM 사용자를 사용하는 것을 권장한다. 하지만 빠르게 테스트를 해보기 위해 우선 루트사용자로 휘젓고 다닐 생각이다.
예전에 gpu 인스턴스 가격 책정해보려고 회사서 까불다가 20만원 날린 기억이 있어서 아예 새로 계정 파고 리전을 서울로 바꿔 한번 새로 싹 시도해보려한다.
codebuild 를 검색해 들어가 새로 코드빌드를 만든다. 응답칸에 레포지토리랑 깃헙 레포지토리에 yml파일 경로도 적어주는 란이 있어서 적어주었다.
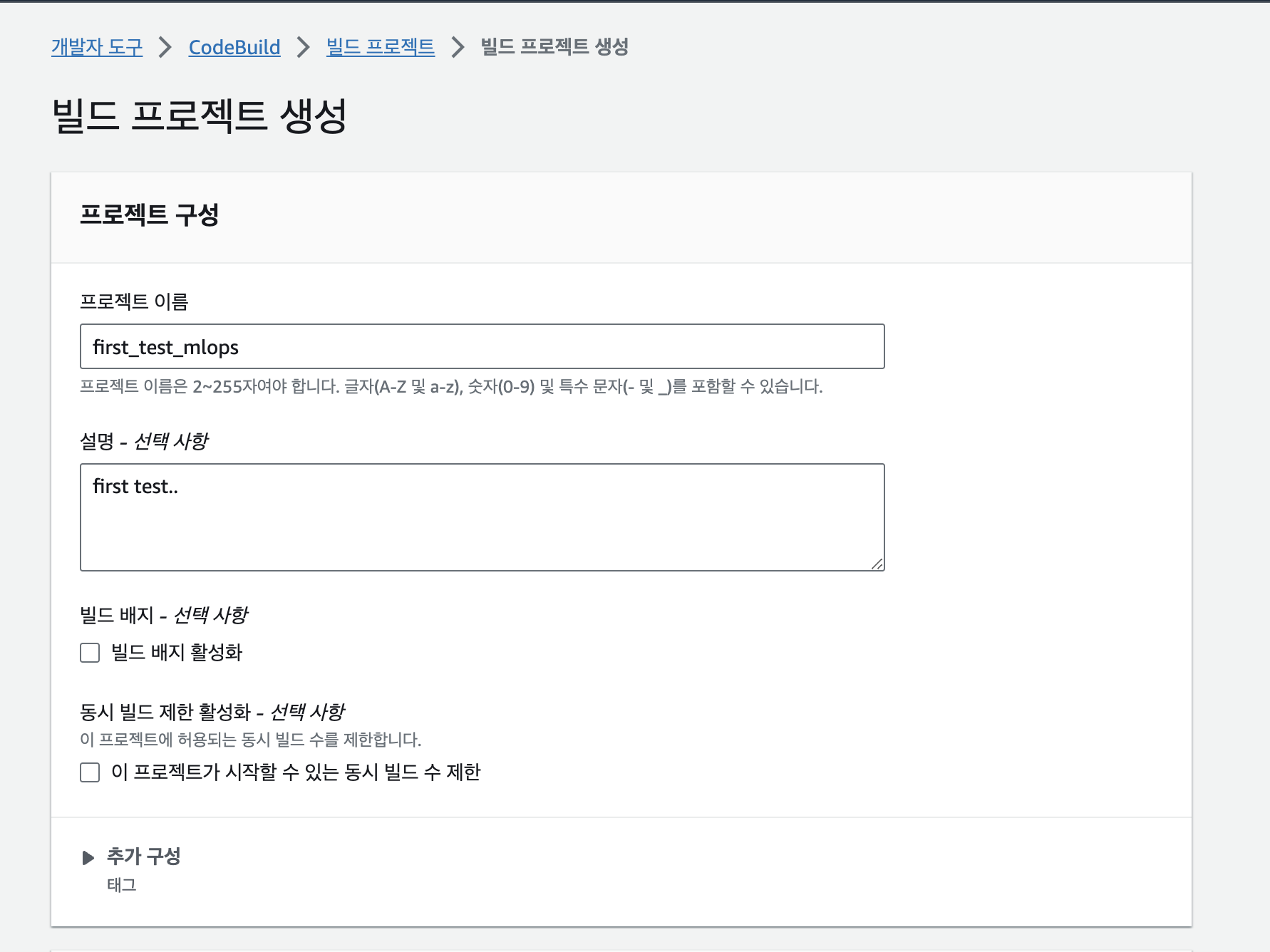
>> 테스트니까 우선 간단간단하게 적을 수 있는 부분만 채워준다.

>> 내 깃헙 레포지토리랑 연결한다. 이 땐 내 깃헙 토큰도 적어서 액세스를 해주어야 연결이 된다.

>> 기본 디폴트 값과 이미지는 스탠다스 5.0, 6.0, 7.0이 있는데 그냥 5.0이 오래되어 가벼워보여서 선택했다.
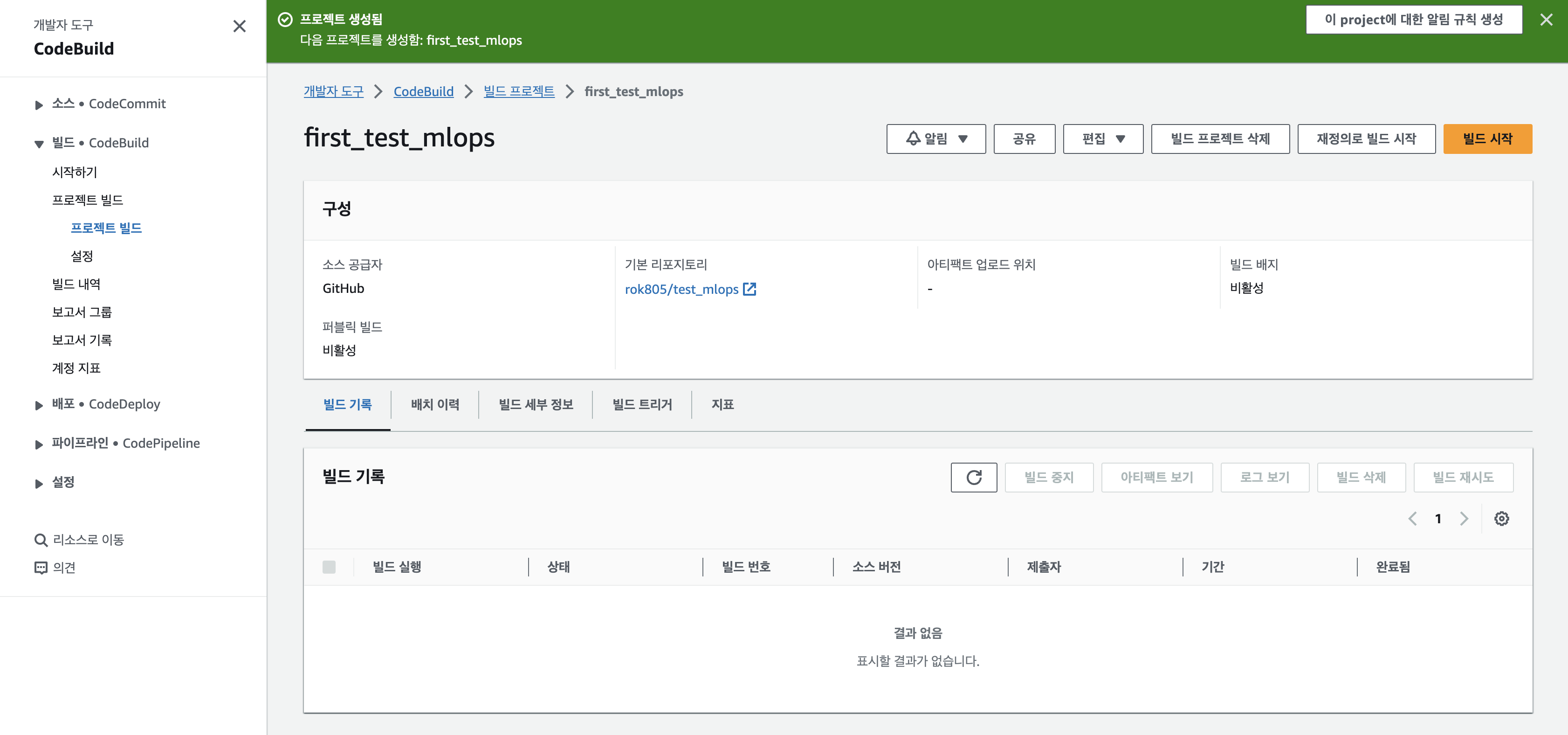
>> 빌드프로젝트가 생성이 되었다. 빌드를 어서 빨리 시작해보자. '빌드 시작' 버튼 클릭!

>> 빌드는 실패했다. 그래서 아래에 단계 세부 정보 배너를 클릭해 로그를 보니 yaml파일을 못찾았다고 한다. 경로가 아마 .github/workflows/main.yml 이었는데 이부분을 지정해주어야하나? 생각이 들어서 고쳐보았다. 하지만 안됐다. 왜냐하면 AWS 에서 codebuild와 깃헙 액션은 서로 다른 서비스이기 때문이다.
어떻게 해결할까? 연동해둔 깃헙 레포지토리의 루트경로에 buildspec.yml 파일로 새로 작성해주어야한다. 기존의 main.yml 파일로 깃헙 액션을 통해 CI를 구성했던 것 처럼 새로운 코드로 아래와 같이 buildspec.yml 파일을 작성해서 깃헙 레포지토리 루트 경로에 업로드 해두어야 한다.
version: 0.2
phases:
install:
runtime-versions:
python: 3.8
pre_build:
commands:
- make install
build:
commands:
- make lint
- make test
post_build:
commands: []
artifacts:
files: []>> 문법이 깃헙 액션에서 사용했던 yml과 좀 다르긴하다. 아무튼 이 파일은 빌드 스펙을 정의한다. 해당 코드가 AWS CodeBuild에 배포되면 각 단계를 실행하게 된다. install은 파이썬을 설정한다. pre_build 단계에서는 사전 빌드 작업을 진행하는데 여기서는 make install 명령을 실행한다. build 단계에서는 빌드 작업을 진행하며 여기서는 make lint, make test 명령을 수행한다. post_build 에서는 빌드 이후에 수행할 작업을 적는데 여기서는 공백이다. artifacts는 AWS CodeBuild 빌드 프로세스가 생성한 결과물을 정의하는 섹션이다. 그래서 해당 결과물을 나중에 다른 aws 서비스로 전송하거나 사용자에게 제공할 수도 있다.

>> 파이썬 3.8 환경으로 빌드 완료. 위 페이지에서 아래로 내리면 로그도 확인가능한데 실제 우분투 cli 에서 실행했을 때와 같은 로그가 출력되는 것을 확인할 수 있다. 이것이 의미하는 것은 우리가 작성한 소스코드들이 정상적으로 모두 잘 작동하였고, 코드가 잘 통합 되었다고 볼 수 있는 단계라고 할 수 있다.
다음에는 깃헙에 main 브랜치에 푸시할 시 깃헙액션으로 ECR에 이미지를 새로 푸시하고, 업데이트된 이미지에 따라 EC2가 자동으로 이미지를 새로 빌드하고 실행중인 컨테이너를 종료 후 재실행시키는 간단한 CI/CD 를 구축해보도록 하겠다.

ref) Practical MLOps by Noah Gift, Alfredo Deza
https://github.com/paiml/practical-mlops-book
GitHub - paiml/practical-mlops-book: [Book-2021] Practical MLOps O'Reilly Book
[Book-2021] Practical MLOps O'Reilly Book. Contribute to paiml/practical-mlops-book development by creating an account on GitHub.
github.com
'MLOps' 카테고리의 다른 글
| MLOps의 필요성.. (0) | 2022.06.15 |
|---|---|
| 딥러닝 모델 컨테이너 띄우기(wt. GPU) (0) | 2022.03.31 |
| nvidia-docker 설치 및 컨테이너 띄우기 with GPU (0) | 2022.03.31 |
| GPU 사용 환경 세팅 (0) | 2022.03.26 |
| MLOps를 위한 잡동사니 (0) | 2022.03.26 |



댓글