728x90
Bag-Of-Words (BOW) : 비정형 데이터를 정형화 하는 방법으로 쓰이는 전통적인 방법이라고 할 수 있다. 각 문서를 사전의 크기 만큼 벡터로 표현한다고 할 수 있다.
우선 바이너리 값으로 있고 없고를 기준으로 한 예시를 보겠다.
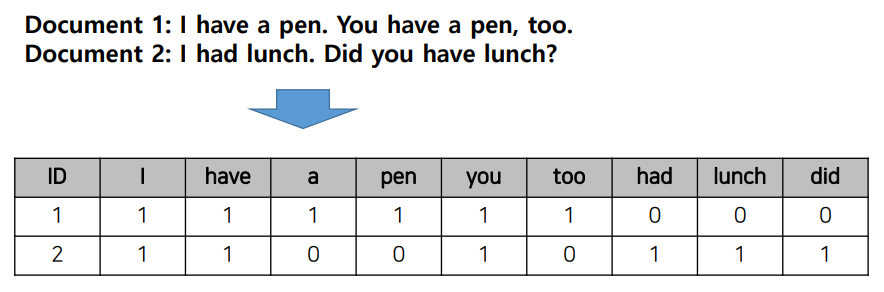
단순 바이너라 값으로 측정된 BOW 행렬은 문서의 특징을 제대로 구별하기 힘들다. 그리하여 단순한 바이너리 값이 아닌 가중치를 주게 되는데, 가장 자주 쓰이는 방법인 TF-IDF 가중치이다.

다음의 행렬속 값들이 변해가는 모습을 차례대로 보며 변화를 살펴본다.



이로써 TF-IDF 가중치로 값을 가지게 된 행렬이 해당 문서의 성격을 상대적으로 잘 나타낼 수 있다. 왜냐하면 TF-IDF가중치의 특징인 "유독 특정 단어가 특정 문서에 많이 나오더라"를 가중치에 녹여냈기 때문이다. 그것이 바로 IDF 이다.
BOW 단점도 잠깐 필기해보면,
1. 너무 스파스(sparse)하다. 0벡터값이 많다는 것.
2.빈도가 많은 단어가 그저 힘이 강하다.
3.단어의 순서를 고려하지 않는다.
4.단어장에 단어가 없는 새로운 단어 처리가 불가능하다.
2번을 해소하려고하는 것이 TF-IDF.
서울과학기술대학교 이영훈 교수님의 강의와 여럿 블로그를 참조하였음을 명시합니다.
728x90
'NLP' 카테고리의 다른 글
| 비정형 데이터 - Classifier_Basic (0) | 2019.12.16 |
|---|---|
| 비정형 데이터 - LSA / pLSA (0) | 2019.12.16 |
| 비정형 데이터 - 전처리 (0) | 2019.12.16 |
| 비정형 데이터 - 소개 (0) | 2019.12.16 |
| 구글 비트코인 뉴스 크롤링 (4) | 2019.11.29 |




댓글