이 장에서는 한 문제에 대한 수백만의 가능한 해답 중 최적 해답을 찾도록 설계된 최적화 알고리즘을 소개한다. 이 알고리즘의 다양한 사용법이 같은 지역을 여행하는 단체 여행객이 최적의 비행편을 찾는 문제와 학생들을 기숙사에 배치하는 가장 좋은 방법 그리고 최소의 교차점을 가지는 네트워크 배치 문제를 통해 소개한다 ~
통계적 최적화(statistics optimization)란 기법을 사용해서 협업 문제를 해결하는 방법에 대해 살펴볼 예정이다. 최적화는 여러 다른 해답을 시도하고 결과 품질을 판단한 후 해답에 점수를 매겨 특정 문제에 대한 최적의 해답을 찾는다. 최적화는 너무 많은 해답을 가지고 있어 전부 시도해 보기 어려운 경우에 일반적으로 사용된다.
-단체 여행 예제
여러 다른 장소에서 출발하여 같은 목적지를 찾아가는 단체 여행을 계획하는 것은 흥미로운 최적화 문제가 된다.
이번 장은"https://github.com/arthur-e/Programming-Collective-Intelligence/tree/master/chapter5" 에 예제를 실습할 수 있게 소스와 데이터가 다행히도 있다.. ㅠㅠ
우선 optimization.py 파일을 생성한다.
import time
import random
import math
people = [("Seymour",'BOS'),
('Franny','DAL'),
('Zooey','CAK'),
('Walt','MIA'),
('Buddy','ORD'),
('Les','OMA')]
# 뉴욕 라구아디아 공항
destination = 'LGA'문제: 가족은 전국에 퍼져 있고, 뉴욕에서 만나길 원한다. 같은 날에 출발해서 같은 날에 도착해야하고
가능하다면 공항 이용 운임을 공유하고 싶어하며,
가족 구성원이 있는 위치에서 뉴욕으로 출발 시간이 다른 수십 편의 비행편이 매일 있다.
또한 다양한 항공 요금과 운행 시간의 비행편이 있다.

이 데이터를 origin과 dest를 키로 하고, 상세 비행편 정보 리스트를 값으로 하여 딕셔너리에 로드하자.
책에서는 python2를 사용하기 때문에 python3로 최대한 바꾸어가며 사용하고 있다.
flights = {}
#
with open('data/schedule.txt','r') as f:
for line in f.readlines():
origin, dest, depart, arrive, price = line.strip().split(',')
flights.setdefault((origin, dest),[])
# 비행편 리스트에 나머지를 넣음
flights[(origin, dest)].append((depart, arrive, int(price)))
flights결과는 아래와 같이 출발/도착 지역에 따라 출발/도착시간과 가격이 나오게 된다.

이제 가족 들이 어떤 비행기에 타야하는지 결정하는데 도전해보자. 경비를 최소로 줄이는 것이 목표지만, 최적화 솔루션이 고려해야하고 또 최소화를 시도해야하는 다른 요소들도 있다. 공항에서의 전체 대기 시간이나 전체 비행 시간이 이에 해당한다. 이런 다른 요소들에 대한 설명을 좀 살펴보자.
예를 들어 위의 딕셔너리에 있는 가족들에 대해서 몇번째비행기를 타고 출발하고 몇번째비행기를 타고 복귀하는지를 리스트로 나열을 해보면 [1,4,3,2,7,3,6,3,2,4,5,3] 사람 머리수의 2배의 개수가 되고, 순차적으로 해석하면 2번째 비행기를 타고 5번째 비행기로 복귀하고, 그 다음 사람은 4번째 비행기를 타고 출발해서 3번째 비행기를 타고 복귀를 한다고 이해하면된다. 하지만 매우 해석 하기가 불편하기 때문에 테이블 형식으로 출력하는 함수를 하나 작성한다.
def getminutes(t):
x = time.strptime(t, '%H:%M')
return x[3]*60 + x[4]
getminutes("14:30")
출력결과는 시간을 분으로 모두 바꾼 것이다.
def printschedule(r):
for d in range(int(len(r)/2.0)):
name = people[d][0]
origin = people[d][1]
out = flights[(origin, destination)][r[d]]
ret = flights[(destination, origin)][r[d+1]]
print ("%10s%10s %5s-%5s $%3s %5s-%5s $%3s" %(name, origin, out[0],out[1],out[2], ret[0],ret[1],ret[2]))
printschedule([1,4,3,2,7,3,6,3,2,4,5,3])결과가 깔끔하게 나왔다.

문제점. 1-가격을 무시. 2-가족들이 함께 공항을 이용하면서 여행하길 원하지만 제각각 도착하는 시간이 다르니 함께 공항을 이용하지는 못한다.
최적 조합 결정을 위해 여러 일정들에 대한 다양한 속성들에 가중치를 매기고 어떤 일정이 최적인지 판단하는 방법이 있어야 한다.
비용함수(cost function)
비용함수는 최적화를 사용해서 문제를 푸는 핵심 열쇠이며 동시에 선택하기 가장 어려운 존재다. 모든 최적화 알고리즘의 목적이 비용함수가 가장 작은 값을 리턴하는 입력집합(이 예제에서는 비행편)을 찾는 데 있기 때문에 비용함수는 한 해답이 얼마나 나쁜지를 표현하는 값을 리턴해야한다. 이 나쁜 정도에 특별한 비율은 없고 해답이 나쁠 수록 큰 값을 리턴하게 된다.
이제 이 예제에서 측정될 수 있는 몇 가지 지표를 생각해 보자.
가격: 모든 비행 티켓의 전체 가격 또는 경제 상황을 반영한 가중평균 가격.
여행시간: 사람들이 비행기 안에 머문 총 시간.
대기 시간: 다른 동반자가 도착하기를 기다리며 공항에서 보낸 시간.
출발 시간: 아침 일찍 출발하는 비행편의 경우 늦잠으로 놓친 여행객에게 추가 비용을 부가할 수 있다.
자동차 렌탈 기간: 여행객들이 차를 빌린다면 가급적 그날 안에 일찍 돌려줘야 한다. 그렇지 않으면 하루치 전체 비용을 추가로 내야한다.
비용을 부과할 변수들을 선택했다면, 그들을 결합하여 한 개의 숫자로 만드는 방법을 결정해야 한다. 예컨데 비행기 안에서 보낸 시간이나 공항 안에서 기다린 시간이 금액으로 환산하면 얼마나 가치 있는지 결정해야한다. 항공 여행에서는 시간 절약을 위해 매분마다 1달러의 비용을 매긴다.(직항으로 1시간을 단축했다면 60달러의 추가비용이 듦을 의미) 또한 공항에서 대기하는 시간을 절약키 위해 매분당 0,5 달러의 추가 비용이 필요하다고 가정해보자.
또한 차를 처음 빌렸을 때 생각했던 시간보다 늦은 시간에 모든 사람이 공항에 도착한다면 자동차 렌탈을 하루 연장하는 데도 추가 비용이 든다.
이제 schedulecost함수를 통해서 이러한 지표를 고려하게 된다. 이 함수는 여행 전체비용과 공항 체류 전체 시간을 고려해야하고, 자동차를 늦게 돌려줬을 때 드는 50달러의 벌점도 생각해야 한다.
def schedulecost(sol):
totalprice = 0 # 전체 비용
latestarrival = 0 #
earliestdep = 24*60
for d in range(int(len(sol)/2)):
# 출발, 도착 비행편을 얻음
origin = people[d][1]
outbound = flights[(origin, destination)][int(sol[d*2])] #짝수번째
returnf = flights[(destination, origin)][int(sol[d*2+1])] #홀수번째
#전체 가격은 모든 출발, 도착 비행편의 가격임
totalprice += outbound[2]
totalprice += returnf[2]
# 가장 늦게 목적지에 도착하는 시간=latestarrival, 가장 먼저 떠나는 시간=earliestdep 설정
if latestarrival < getminutes(outbound[1]): latestarrival=getminutes(outbound[1])
if earliestdep > getminutes(returnf[0]): earliestdep=getminutes(returnf[0])
#모든 사람들은 가장 늦게 도착하는 사람을 공항에서 기다려야 한다.
#또 이들은 도착하는 동시에 출발 비행편을 기다려야 한다.
totalwait = 0 # 기다리는 시간(분): 빨리 도착하는 만큼 손실이 적음. 늦게 출발하면 출발할수록 손실이 적음.
for d in range(int(len(sol)/2)):
origin = people[d][1] # 도착시간
outbound = flights[(origin, destination)][int(sol[d])] #뉴욕으로 출발하는 시간
returnf = flights[(destination, origin)][int(sol[d+1])] #고향 도착 시간
totalwait += latestarrival - getminutes(outbound[1]) # 가장 늦게 도착하는 사람의 시간(분총합) - 뉴욕 도착하는 시간(분총합) = 기다린 시간
totalwait += getminutes(returnf[0])-earliestdep # 고향으로 출발하는 시간(분총합) - 가장 먼저 떠나는 사람의 시간(분총합) = 기다린 시간
# 만약 다 도착하기도 전에 누군가 출발해야 한다면 추가적으로 렌탈비 명목으로 50달러 추가
if latestarrival > earliestdep:
totalprice+=50
return totalprice + totalwait
s = [1,4,3,2,6,3,6,3,2,4,5,3]
schedulecost(s)
# 결과 : 4366
printschedule(s)
단순하지만 핵심은 설명하고 있다. 가족들이 전체적으로 빨리 도착하면 도착할수록 개개인의 기다리는 시간이 줄어들어 손실이 적어지고, 고향으로 다시 돌아가는 출발 시간이 늦어질수록 손실이 줄어든다. 즉 빨리 빨리 오면 빨리빨리 다 만나는거고, 한사람이 또 너무 빨리 가면 그만큼 기다려야하는 시간이 늘어나기 때문에 그렇다. 너무 복잡하게 생각하지는 말자 !
함수에 지표에 대해서 세부적으로 바꾸어 보는 생각도 해볼 수 있다. 전체 대기 시간을 계산할 때 마지막 사람이 도착한 때에만 가족 전체가 함께 공항을 떠나 가장 빨리 출발하는 공항으로 갈 것이라 했는데, 이 조건을 두시간 이상 기다린 사람은 자신의 차를 빌리며 가격과 체류 시간을 적당히 조정할 수 있는 것으로 변경할 수 있다.
이론상 모든 조합을 다 시험해 보아야 하지만 이 예제에서는 16개의 비행편과 9개의 가능성이 있으므로 $16^{9}$ (약3천억개)개의 조합을 가진다. 모든 조합을 시도하는 것이 좋지만 컴터 연산이 오래 걸릴 것이다. (실제 깃헙에서 불러온 예제 데이터는 12개의 비행편과 10개의 가능성이라서 $12^{10}$ 으로 계산된다.)
무작위 검색(random searching)
무작위 검색은 좋은 기법이 아니다. 하지만 모든 알고리즘이 하려는 점을 정확히 이해하는데 좋으며, 다른 알고리즘이 잘 동작하는지 볼 수 있는 기준선이 되어준다.
이 함수는 여러 개의 인자를 가진다. domain은 2개 튜플의 리스트로 각 변수의 최솟값과 최댓값을 가진다. 해답의 길이는 이 목록의 길이와 동일하다. 현재의 예에서는 모든 사람에 대해 9개 출발 비행편과 9개 도착 비행편이 있어서 리스트 내에서 domain은 (0,8)이 되고, 각 사람별로 두번씩 반복된다.
두번째 인자인 costf는 비용함수로, 이 예제에서는 schedulecost가 된다. 이 함수는 인자로 전달되기 때문에 다른 최적화 문제에서도 재활용될 수 있다. 이 함수는 무작위로 1,000 추정값을 생성하고 그들에 대해 costf를 호출한다. 또한 최적의 추정값(가장싼비용을가지는것)을 추적하여 리턴한다.
import random
def randomoptimize(domain, costf):
best = 999999999
bestr = None
for i in range(10000):
#무작위 해답을 생성한다. # 즉 위에서 본 리스트들을 랜덤으로 만들어본다고 할 수 있다.
r=[random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))]
#비용을 구함
cost = costf(r)
#이제까지의 최적 값과 비교함
if cost < best:
best = cost
bestr=r
return rdomain = [(0,9)] * (len(people)*2)
s = randomoptimize(domain, schedulecost)
schedulecost(s)
# 결과: 5518
printschedule(s)
여러번해서 비용함수가 처음 예보다 적은게 나올 때까지 수행해보고 이 결과를 보았는데, 뉴욕에 도착해서 그래도 여전히 12시간씩 기다려야하는 상황이 있긴하다. 고향으로 다시 갈때도 마찬가지.. 루프를 늘려보면 더 좋겠지만 무식하게 막 돌리지 말고 최적화를 통해 계산시간을 효율적으로 줄여보는 방법을 알아보자.
언덕등반(hill climbing): 무작위 검색의 대안.
무작위 해답으로 시작해서 더 좋은 해답(낮은 비용 함수를 보유함)을 찾아 이웃 해답들을 살펴보는 기법이다. 아래의 그림처럼 경사면에 무작위로 내가 놓여있다고 생각해보자. 물을 찾기 위해 가장 낮은 점에 도착하길 원한다고 가정해보자. 그렇다면 각 방향을 살펴보고 지표면 경사가 가장 아래방향으로 심하게 기울어진 곳을 향해 걸어야 한다. 평평한 장소나 언덕 위로 경사가 시작된 점에 도착할 때 까지 가장 심하게 기울어진 방향으로 계속해서 걸어가야한다. similar 경사하강법. 이를 예제에 적용해보면 최적 여행 일정을 찾는 작업에 적용시킬 수 있다. 무작위 일정에서 시작해서 모든 근처 일정을 찾으면 된다. 이런 경우는 한 사람이 가질 수 있는 모든 일정들 중 바로 이전이나 이후 비행편을 검색해야 함을 뜻한다.
이웃 일정들에 대해 비용을 계산해서 최저 비용을 가진 일정이 새로운 해답으로 된다. 이 과정을 이웃 일정이 더 이상 비용을 개선하지 못할 때까지 반복한다.

def hillclimb(domain, costf):
#무작위 해답을 생성함
sol=[random.randint(domain[i][0], domain[i][1]) for i in range(len(domain))] # 0~9 까지 각각 한자리 정수를 출력 (n1, n2)
#메인 루프
while 1:
#이웃 해법의 목록을 생성함. neighbors
neighbors=[]
for j in range(len(domain)): #0~11까지 총 12번 반복
#각 방향별로 한 개씩 선택함
if sol[j] > domain[j][0]:
neighbors.append(sol[0:j] + [sol[j]-1] + sol[j+1:])
if sol[j] < domain[j][1]:
neighbors.append(sol[0:j] + [sol[j]+1] + sol[j+1:])
#이웃 중에 최적 해답을 살펴봄
current = costf(sol)
best = current
for j in range(len(neighbors)):
cost=costf(neighbors[j])
if cost<best:
best=cost
sol=neighbors[j]
#개선되지 않으면 최적 해답임
if best==current:
print(best)
break
return sol
nei=hillclimb(domain, schedulecost)
schedulecost(nei)
#결과: 2482
printschedule(nei)
위에 보이는 리스트들이 차원하나하나마다 이웃을 보고 더 낮은 비용을 갖는지를 비교하게 된다. 많지 않은 표본임에도 결과가 나쁘지 않은 것을 알 수 있다. 하지만 ~~!
언덕등반 방식에는 큰 결점이 있다.
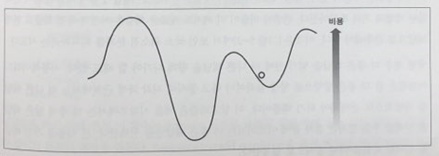
그림을 보면 단순히 경사를 따라 내려가는 방식으로는 어느 곳에서나 항상 최적의 해답에 도달할 수 있을까? 절대 그렇지 않다. 출발지점이 어디냐에 따라서 최저점을 각기 다르게 가질 수 있으며 그러한 지역최저점(local minimum)과 전체에서 가장 낮은 지점(global minimum)이 일치하기가 힘들다. 랜덤으로 initial state 를 잡고 시작했기 때문이다.
이러한 딜레마에 대한 해결책으로 무작위 재시작 언덕등반(random-restart hill climbing)이 있다. 무작위로 시작점을 몇 개 선택한 후 무작위로 선택한 시작점 중 하나가 전역 최소점에 근접할 것이란 희망을 가지고 언덕등반 알고리즘을 진행한다.
다음장에서 '시뮬레이티드 어닐링'과 '유전자 알고리즘' 을 통해 local minimum에 빠지는 것을 회피하는 방법들을 살펴본다.
'Programming_Collective Intelligence > 5.최적화' 카테고리의 다른 글
| 선호도 최적화 (0) | 2020.01.04 |
|---|---|
| 시뮬레이티드 어닐링/유전자 알고리즘 (0) | 2020.01.03 |


댓글