위키피디아에서의 추천시스템; 정보 필터링(Information Filtering)기술의 일종으로, 특정 사용자가 관심을 가질만한 정보(영화, 음악, 책, 뉴스, 이미지, 웹 페이지 등)를 추천하는 것이다.
추천시스템의 종류에는 현재 가장 많이 사용하는 협업필터링(Collaborative filtering) 기법이 있고, 이외에 콘텐츠 기반 필터링(Content-based filtering), 하이브리드 추천시스템(Hybrid recommender systems) 등이 있다.
1. Collaborative filtering: 협업 필터링이라고 불리는 이 필터링 기법은 우선 위키피디아의 정의를 보면 사용자의 행동, 활동 또는 선호도에 대한 많은 정보를 분석하고 모으고 다른 사용자와의 비슷함에 기초를 두고 사용자들이 무엇을 좋아할 지를 예측하는 것에 기초를 두고 있다.
사용자 간의 유사도를 측정하여 비슷함을 판단한다. 유사도를 계산하는데 있어서 사용자가 기하급수적으로 증가하게 되면 계산량이 너무 많아지므로 이를 보완하기 위해 K-nearest neighbor , Clustering 알고리즘을 사용하여 유사집단을 분류한다.
사용자와의 비슷함에 기초;(Collaborate filtering은 과거에 동의한 사람들이 미래에도 동의하고 그들이 그들이 과거에 좋아했던 것들을 좋아할것이라는 가정에 기초를 두고 있다.) 즉, 사용자의 아이템 선호가 유행을 따르거나, 일정한 패턴을 가지고 있다는 사실에 근거한다는 의미이다.
-한 블로그(yeomko.tistory.com)에서 이해하기 쉽게 한 문장으로 요약되어 있는 것을 가져왔습니다.
"""내가 남긴 평점 데이터를 가지고
나와 취향이 비슷한 사람이 선호하는 아이템을 추천한다."""
"""사용자 혹은 아이템에 대한 프로필 데이터를 가지고
내가 좋아했던 아이템과 비슷한 유형의 아이템을 추천하거나
나와 비슷한 유형의 사람이 좋아하는 아이템을 추천"""
하지만 아래의 단점 중 3번에 해당하는 문제가 있습니다. 이에 평가를 받지 않은 상품에 대한 사용자의 평가를 예측하게 됩니다. 그리고 가장 평가를 높게 할 것으로 예측되는 상품을 사용자에게 추천해주는 방식으로 흘러가게 됩니다.
장점:
1. 추천 항목에 제한이 없다.
단점:
1. 동일한 항목을 평가한 사용자 수가 많지 않다. (sparse matrix 문제)
2. 다수의 사용자에 대한 데이터가 필요하다. (cold start 문제)
3. 평가를 받지 않은 상품에 대해선 추천이 불가능하다.
4. 유명한 항목 위주로 추천을 하게 된다.
* Collaborative filtering concept
Memory based(메모리 기반)
- User based(사용자 기반): 유저들이 남긴 평점을 기반으로 '나'와 가장 유사한 유저(k명)를 구하고, 내가 남기지 않은 품목에 대한 평점을 유사한 유저들의 가중치를 사용하여 아이템을 추천.
- Item based(아이템 기반): 유저들이 남긴 평점을 기반으로 아이템 간의 유사도를 구하여 사용자가 높게 남긴 평점
Model based(모델 기반)
- Latent Factor(잠재 요소)
- Matrix Factorization(행렬 분해)
- SVD(singular vector decomposition)(특잇값 분해)
평점 데이터는 성격에 따라서 Explicit Dataset과 Implicit Dataset으로 구분지을 수 있다고 합니다.
implicit; 암시된, 내포된
explicit; 분명한, 명쾌한
Explicit Dataset은 사용자가 아이템에 대하여 선호와 비선호를 명확하게 구분해준 데이터셋이라고 합니다. 예를 들면 좋은 평가로 5점을 주고 나쁜 평가로 1점을 주는 경우입니다.
Implicit Dataset은 위의 데이터셋과는 다르게 사용자의 평가가 명확하지 않은 경우의 데이터셋이라고 하면 될 것 같습니다.
5점, 1점 등과 같은 호불호 정보 없이 사용자가 아이템을 얼마나 소비하였는지(행동의 빈도수)를 기록한 데이터 셋이라고 합니다.

Explicit Dataset은 '?' 부분에 해당하는 영역을 제외하여 사용자의 선호도를 학습하고 예측을 합니다.
Implicit Dataset은 '?' 부분에 해당하는 영역을 포함하여 사용자의 선호도를 학습하고 예측을 합니다.
CF(Collaborative Filtering) 방법은 모든 사용자의 데이터를 균일하게 사용하는 것이 아니라 평점 행렬이 가진 특정한 패턴을 찾아서 이를 평점 예측에 사용하는 방법이다. 이에 사용자나 상품 기준으로 평점의 유사성을 살펴보 Neighborhood model과 행렬의 수치적 특징을 이용하는 Latent Factor model이 있습니다.
Neighborhood model: Memory-based CF라고도 하며, 특정 사용자의 평점을 예측하려고 사용하는 것이 아니라! 해당 사용자와 유사한(similar) 사용자에 대해 가중치를 주는 것입니다. 측 주어진 평점 데이터를 가지고 유사도(주로 피어슨 상관계수를 사용한다고 합니다.)를 측정하여 유사한 사용자를 찾아냅니다. [3][4]
1. 사용자 간의 유사도를 구해준다. 아래는 유사도를 구하는 방법들이다.
- 피어슨 유사도(Pearson Similarity)

- 평균제곱차이 유사도(Mean Squared Difference Similarity): 유클리드 공간에서의 거리 제곱에 비례하는 값이다. msd 값을 구하고 그 역수로 유사도를 정의한다. msd값이 0이 될 수 있으므로 msd값에 1을 더해준다.



사용자 간의 msd는 그 두사람이 각각 평가한 아이템의 평점의 차에 제곱을 하고 그 들의 합을 그들이 둘 다 평가한 상품의 개수로 나누어 유사도를 구하는 것이다. 유클리디안 거리를 생각하면 쉬울 것같다.
- 코사인 유사도(Cosine Similarity): 두 특성 벡터의 각도에 대한 코사인 값을 말한다. 각도가 0도이면 코사인 유사도는 1이 되고 각도가 90도가 되면 유사도는 0이 된다.


2. 유사도를 토대로 유사한 사용자를 알 수 있고, 이에 나와 유사한 사용자의 자료를 토대로 아이템을 추천한다. 유사도를 통하여 아이템을 추천하는 방법은 아래의 방법들과 같다.
- K-nn(K Nearest neighbors): 일단 유사도가 구해지면 평점을 예측하고자 하는 사용자(또는 상품)와 유사도가 큰 k 개의 사용자(또는 상품) 벡터를 사용하여 가중평균을 구해서 가중치를 예측한다. 이러한 방법을 KNN 기반 예측방법이라고 한다. surprise 패키지에서는 다음과 같은 3가지의 KNN 기반 가중치 예측 알고리즘 클래스를 제공한다.
- KNNBasic: 평점들을 단순히 가중 평균한다.

-KNNWithMeans: 평점들을 평균값 기준으로 가중평균한다. 이는 위의 식의 경우 $r$값의 척도가 다르게 측정된 경우를 전혀 고려하지 않는다는 점을 보완할 수 있다.

-KNNBaseline: 평점들을 베이스라인 모형의 값 기준으로 가중 평균한다.

아이템 기반의 CF
- 아이템 간의 상관관계를 분석하기 위하여 가장 유사도가 높은 K개의 아이템을 묶어줄 수 있습니다. 특정 사용자가 아직 평점을 남기지 않은 아이템을 추천해야할 경우, 이 K개의 가까운 이웃들에게 사용자가 남긴 평점들을 가지고 해당 아이템에 내릴 평점을 예측하게 됩니다. 이를 Item-oriented Neighborhood라 합니다.
- 쉽게 설명하면 특정 사용자 $u$ 가 평가하지 않은 $i$에 대한 예측 평점은 과거에 $u$가 평가한 다른 아이템들 $j$ 들과 $i$ 사이의 유사도를 통해서 계산하는 것이다.
콘텐츠 기반과 비슷하다고 생각할 수도 있겠지만, 아이템 간의 유사도 행렬은 다른 사용자들의 평점이 반영되기 때문에 순수한 콘텐츠 기반이랑 다르다.
그리고 아이템 기반의 CF는 사용자 기반 보다 더 나은 성능을 제공할 수 있다고 한다.
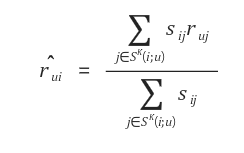

Latent Factor 모형: 사용자의 특성 벡터나 상품의 특성 벡터의 길이는 수천에서 수십억에 달하는 긴 크기가 될 수 있다.(상당히 sparse한 matrix가 될 가능성이 농후하다.) 그래서 이 모형은 이렇게 긴 것을 몇 개의 요인 벡터로 간략화(approximate)할 수 있다는 가정에서 출발한 모형이다.
PCA(Principal Component Analysis)를 이용하면 긴 특성 벡터를 소수의 차원으로 차원 축소할 수 있듯이 사용자의 특성도 차원 축소 할 수 있다.
Matrix Factorization: 모든 사용자와 상품에 대해 다음 오차 함수를 최소화하는 요인 벡터를 찾아낸다. 아래의 행렬에서 P, Q를 찾는다.
Implicit Dataset이 주어질 경우, Latent Factor 모델 중 Matrix Factorization이 적합하다.


평점 행렬인 R을 사용자 행렬(P)과 아이템 행렬(Q)로 쪼개는 것입니다. 그리고 나서 쪼개어진 이 Latent Factor행렬을 학습시킵니다. 요인 k 즉, 차원은 사용자가 학습 시에 정해주는 파라미터라 생각하면 되고(보통 50~200으로 한다고 합니다.), 이 P,Q 는 R에 있는 값과는 무관하게 아주 작은 랜덤 값들로 초기화 됩니다.



특정 사용자의 latent vector와 특정 아이템의 latent vector의 내적으로 특정 사용자의 특정 아이템에 대한 예측 평점을 구하는 것을 알 수 있습니다.
이제 위의 X, Y를 학습시키기 위한 Loss Function을 구하게 되는데 예측 평점 행렬의 오차가 최대한 작아지도록 수식을 구성합니다.

앞 부분은 잔차 제곱이라고 생각하면 될 것 같고, 뒷 부분은 각 제곱합을 더한 값에 감마를 곱해주는데(L2 regularization) 감마는 실험을 통해 조절해나가도록 합니다.
SVD(Singular Value Decomposition): Matrix Factorization 문제를 푸는 방법 중 하나로, m x n 행렬 R을 세 행렬의 곱으로 나타내는 것이다.

2. Content-based filtering: 컨텐츠 기반 필터링이라 불리는 이 필터링 기법은 마찬가지로 위키피디아의 정의를 보면 item에 대한 특징과 사용자 선호에 대한 profile을 기반으로 한다. 가장 많이 사용되는 방법은 TF-IDF 이다. TF-IDF로 만들어진 행렬을 토대로 클러스터링을 하여 대상 아이템과 같은 군집 속에 있는 아이템들을 추천해준다.
즉 아이템 간의 연관성을 분석해서 연관성이 높은 다른 아이템을 찾아서 보여준다고 생각하면 된다. 예) 뉴스 추천
-한 블로그에서 이해하기 쉽게 한 문장으로 요약되어 있는 것을 가져왔습니다.
장점
1. 다른 사용자의 데이터가 필요하지 않다.
2. 유명하지 않은 새로운 항목을 추천해볼 수 있다.
3. 신규 항목을 추천할 수 있다.
4. 추천한 이유를 설명할 수 있다.
단점
1. 아이템의 특성에 관한 데이터가 적다.
2. 사용 이력이 없는 신규 사용자에게 추천이 불가능하다.
3. 사용자에게 종속적인 추천 방식이다.
refererence
[1] wikipedia
[2] An Online Review Mining Approach to a Recommendation System.
[4] https://datascienceschool.net/view-notebook/fcd3550f11ac4537acec8d18136f2066/
'추천시스템' 카테고리의 다른 글
| MovieLens 데이터를 활용한 Collaborative Filtering 구현 (0) | 2020.01.15 |
|---|---|
| 콘텐츠 기반 필터링 추천 예제 (0) | 2020.01.14 |
| 연구주제를 위한 논문 리뷰 (0) | 2020.01.10 |
| 사용자간 유사도를 활용한 협업필터링 추천 예제 (0) | 2019.11.24 |
| 사용자간 유사도 계산 (0) | 2019.11.23 |




댓글