MovieLens 데이터를 가지고 CF 의 기법인 사용자 기반, 아이템 기반 필터링을 구현해보도록 한다.
추천시스템 연구 분야의 경우 성능을 평가하거나 다른 알고리즘의 변형을 공식적인 데이터들을 통해서 비교하고, 기준 등을 명확히 한다. 이 MovieLens 데이터는 많은 논문에서 공식적으로 사용되어 성능 평가 등을 측정하는데 사용되곤 하였다.
데이터의 출처는 다음과 같다.
https://grouplens.org/datasets/movielens/

압축을 풀고 그 안에 있는 ratings.csv 파일과 movies.csv 파일을 활용하였으며, 파이썬을 사용하였다.
불러온 데이터는 아래와 같다.
- 데이터 불러오기
movies.csv 데이터(케이스 수 62424)
movies=[]
with open('movies.csv','r',encoding='UTF-8') as f:
for line in f.readlines():
movies.append(line.strip().split(","))
pd.DataFrame(np.array(movies[1:10]),columns=movies[0])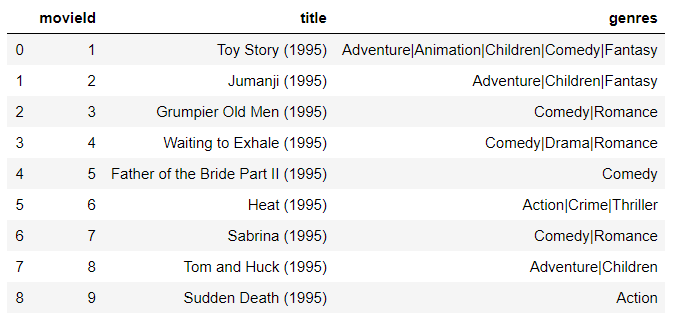
ratings.csv 데이터(케이스 수: 25000096, user 수: 162541)
ratings=[]
with open('ratings.csv','r',encoding='UTF-8') as f:
for line in f.readlines():
ratings.append(line.strip().split(","))
pd.DataFrame(np.array(ratings[1:10]),columns=ratings[0])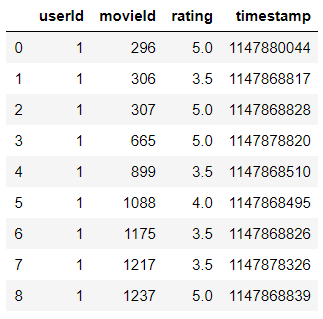
- 데이터 전처리
CF에 우선 필요한 데이터인 ratings 데이터를 주로 사용하기 때문에 ratings 데이터 위주로 코드를 구현하였다.
딕셔너리 형태로 바꾸어주는 함수.
# ratings_df 을 토대로 딕셔너리 형태로 바꾸는 함수.
def ratings_dictionary(ratings):
r_dict = {}
for i in ratings[1:]:
if i[0] not in r_dict.keys():
r_dict[i[0]]={i[1]:float(i[2])}
else:
r_dict[i[0]].setdefault(i[1],float(i[2]))
return r_dict
<- 이런형태로 사용자 x 아이템 평가 데이터를 만들어 주는 것이다. 데이터 프레임을 사용할 경우 엄청나게 많은 sparse들을 피하고 계산 성능을 올려주기 위해 딕셔너리를 사용한다.
추천 시스템에서 계산 성능은 피할 수 없는 중요한 문제이다.
코사인 유사도를 구하는 함수
import math
import numpy as np
def cosine_similarity(A,B): # ex) A=[2.0, 3.0] , B=[5.0, 3.5] ; 리스트 속 수치형 자료, 당연히 차원이 같아야함.
dot_p = np.dot(A,B)
A_norms = math.sqrt(sum([i**2 for i in A]))
B_norms = math.sqrt(sum([i**2 for i in B]))
AB_norms = A_norms * B_norms
return dot_p / AB_norms # 1에 가까울수록 유사함.
1,2 를 통해 필터링에 들어가기 앞서, 아래에 나와있는 공식들은 특정 사용자에게 단 하나의 아이템에 대한 예측 평점을 구해주는 것이지만 내가 구현하여 얻고자 하는 것은 특정 사용자에게 평점이 없는 모든 아이템에 대한 예측 평점을 구하고 내림차순으로 정렬하는 결과를 도출하는 것이다.
1. 사용자 기반 필터링
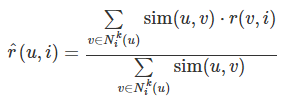
- 유사도는 코사인 유사도를 사용하고, 위의 공식처럼 KNN 기법을 활용하여 $u$가 평가하지 않은 아이템들에 대한 예측을하는 함수.
# KNN 기반의 사용자 기반 필터링 기법을 사용한 특정 유저에 대한 추천 영화.
# 모든 영화 id
all_m=[i[0] for i in movies[1:]]
import operator
def user_based_filtering(rating_dict, person, similarity=cosine_similarity, k=3):
#1. person과 다른 사용자들 사이에서 둘 다 평가한 영화를 토대로 유사도를 구한다.
person_m = set(rating_dict[person].keys()) # person이 시청한 영화.
similar_score={} # 사용자간 유사도 결과.
for other_person in rating_dict.keys():
both_m = person_m.intersection(set(rating_dict[other_person].keys()))
if len(both_m) >= 1: #공통된 영화가 1개 이상인 경우만 고려함. 0개면 유사도 못구함.
#2. person의 both_m의 평가점수, other_person의 both_m에 대한 평가점수 사이의 유사도를 구한다.
person_m_rating = [rating_dict[person][i] for i in both_m]
other_person_m_rating = [rating_dict[other_person][i] for i in both_m]
score= cosine_similarity(person_m_rating, other_person_m_rating)
similar_score[other_person]=score
# 공통으로 평가한 영화가 없으면 사용자 간의 유사도 측정이 불가능하다. <- 한계
#2. 유사도를 내림차순으로 정렬하여 유사도 기반 이웃들을 생성함.
neighborhood=sorted(similar_score.items(), key=operator.itemgetter(1), reverse=True)
print("특정 사용자와의 유사도 : \n\n",neighborhood[:50])
#3. 내가 평가하지 않은 아이템들을 추출하고, 그 아이템을 평가한 유사도 기준 이웃 k 명의 평가를 토대로 가중평균을 구함.
people_for_recommendation = [i[0] for i in neighborhood] # person과 유사도를 구했던 사용자들
no_watch_m = set(all_m) - person_m # 내가 평가하지 않은 아이템
recommendation_of_movies = {} # 추천 결과
a=1
for movie in no_watch_m:
r=[]
s=[]
for person in people_for_recommendation:
if movie in rating_dict[person].keys():
r.append(rating_dict[person][movie]*similar_score[person])
s.append(similar_score[person])
else:
continue
if (sum(r) == 0) | (sum(s)== 0) : # 내가 평가하지 않은 아이템에 역시 누구도 평가하지 않았다면 패스.
continue
elif len(r) <= k: # k 보다 적은 경우에는 어쩔 수 없이 있는 사용자들끼리의 가중평균을 구함.
recommendation_of_movies[movie] = sum(r)/sum(s) # 하나의 영화에 대한 예측 평점
else: # k 보다 아이템에 평가한 사용자가 많다면 k 까지만의 평점을 가지고 가중평균을 구함.
recommendation_of_movies[movie] = sum(r[:k])/sum(s[:k]) # 하나의 영화에 대한 예측 평점
return sorted(recommendation_of_movies.items(), key=operator.itemgetter(1), reverse=True)[:1000]
위의 함수를 아래 처럼 실행시켜 보았다. 아래는 유사도는 저기 위에서 구한 코사인 유사도 함수를 사용하여 생략, k도 역시 마찬가지로 default로 설정해놓은 3을 사용할 것이기 때문에 생략하였다. 데이터는 평점 딕셔너리, 추천 대상자는 '1'번 이며, 자동적으로 '1'번 사용자와 유사한 순서대로 50명이 출력이 된다.
recommendation_1000 = user_based_filtering(r_dict, '1')
추천 결과는 아래와 같다. 1000개 까지 출력하도록 하였다.
pd.DataFrame(recommendation_1000)
고민할 점
1. 내가 평가하지 않은 아이템을 평가한 사용자라도 나와 유사도를 구할 수 없었다면(공통 항목에 대해 평가한 적이 없음.) 제외시켜야함. => $sim(u,v)$가 존재할 수 없기 때문.
2. 나와 유사도가 1인 이웃이 있다. 그 이웃은 나와 공통으로 항목에 평점을 매긴 수는 오직 1개이다. 내가 누군가와 특정 한가지 아이템에 대해서 완전히 동일한 평점을 줄 가능성은 현실세계에서 농후하다고 생각이 든다. 그렇기 때문에 더 많은 데이터를 모아 극단적인 예들의 영향력을 줄여준다. 하지만 계산량에도 한계가 있을 것이므로, 제한된 범위 내에서 유사도를 잘 측정하는 방법에 대해서 더 공부해야겠다.
3. k에 따라서 추천이 달라지게 될텐데, 그렇다면 나와 공통으로 평가한 항목이 없어서 나와 취향이 비슷함에도 무시당한 사용자 $v$들을 끌어들이는 방법도 생각해볼 만하다.
2. 아이템 기반 필터링
$\hat{r}(u,i) = \frac{\sum_{j\in N_{u}^{k}(j)} sim(i,j) \cdot r(u,j)}{\sum_{j\in N_{u}^{k}(j)} sim(i,j)}$
사용자 기반 필터링과는 사뭇 다르다는 사실을 위 공식을 통해서 알 수 있다. 왜냐하면 아이템 기반 필터링에서는 내가 평가하지 않은 아이템 $i$ 와 다른 아이템간의 유사도를 활용하기 때문이다.
분모에 $\sum_{j\in N_{u}^{k}(j)}$ 는 사용자 $u$ 가 평가했던 아이템 $j$ 들이다. 그러므로 아이템 간의 유사도의 총합이 된다.
분자에 $\sum_{j\in N_{u}^{k}(j)}sim(i,j) \cdot r(u,j)$ 는 사용자가 평가한 $j$의 평점과 아이템 $i$와 $j$간의 유사도의 곱들을 모두 구해서 합한 값이다.
차이점은 이렇다.
1. 아이템간의 유사도를 구해야한다는 것.
2. 특정 사용자 $u$ 가 이전에 다른 아이템에 준 평가를 사용한다는 점.
3. 논문에 따르면 경험적으로 더 나은 성능을 보였다고도 한다.
-> Item-Based Top-N Recommendation Algorithms(2004)
4. 사용자 기반 필터링에서는 특정 사용자와 유사도를 구할 수 있는 사용자와 평점 벡터를 가지고 유사도를 구했다면,
아이템 기반 필터링에서는
1. " $i$에 대한 내 예측 평점은 뭘까? 내가 지금껏 $j$들에게 준 평점들을 주긴했는데... 어디 $j$에 평점을 준사람들 없나?"
2. " $j$에 평점을 준 사람들이다! 이 사람들 중에서 $i$ 에 평점도 준 사람들이 있을까?"
3. " 내가 $j$에 준 평점과 그들이 $j$에 준 평점, 그리고 그들이 $i$에 준 평점들을 가지고 $i$ 에 대한 내 예측 평점을 구해볼 수 있겠다."
-> 이렇게 적어도 이상하게 머릿속에서 이해가 안가서 너무 힘들었다......... 사용자 기반은 금방 이해가 됐는데 말이다......
$u$ 의 과거 $j$를 평가했던 이력 + $j$와 $i$를 동시에 평가한 평점을 가지고 구한 유사도$(i, j)$ => $u$의 $i$ 예측 평점
아래는 아까와 동일한 데이터를 사용하여 파이썬을 활용해 구현한 코드이다.
코드 구현은 먼저 아이템 간의 유사도(사용자가 평가한 $j$ 개수 x 평가 안한 $i$ 개수 만큼의 계산)를 구하고, 이후에 모든 $i$(사용자가 평가하지 않은 아이템)에 대해서 예측 평점을 구한다.
import operator
def item_based_filtering(rating_dict, person, similarity=cosine_similarity, k=3):
# 평가하지 않은 모든 i 들과 평가한 모든 j 사이의 예측 평점을 모두 구하면서 각 i마다 예측평점을 구한다, 내림차순으로 출력한다.
tmp = [list(r_dict[i].keys()) for i in list(r_dict.keys())] # 임시
no_rating_m = list(set([j for i in tmp for j in i])) # # 평가하지 않은 모든 영화
rating_m = [i for i in list(rating_dict[person].keys())] # # person이 평가한 모든 영화
#1. 아이템 간의 유사도를 모두 구한다.
c_s={}
for i in no_rating_m:
c_s[i]={}
for j in rating_m:
p_i=[]
p_j=[]
for p in list(rating_dict.keys()):
if j in rating_dict[p].keys() and i in rating_dict[p].keys():
p_i.append(rating_dict[p][i])
p_j.append(rating_dict[p][j])
if len(p_i)>0:
c=cosine_similarity(p_i, p_j)
c_s[i].setdefault(j,c)
#2. 모든 i에 대한 예측 평점을 구한다. considering k .
result = {}
for i in list(c_s.keys()):
sum_sim_rating=[]
sum_sim=[]
k_i_j = sorted(c_s[i].items(), key=operator.itemgetter(1), reverse=True)[:k]
for j in k_i_j:
sum_sim.append(j[1])
sum_sim_rating.append(j[1]*rating_dict[person][j[0]])
if len(sum_sim) > 0:
result[i]=sum(sum_sim_rating)/sum(sum_sim)
return sorted(result.items(), key=operator.itemgetter(1), reverse=True)
r= user_based_filtering(r_dict, '1', similarity=cosine_similarity, k=3)
r
의견:
우선 부족한 코딩실력 때문인지 계산 시간 차이가 너무 많이 나서, 아이템 기반에서는 아쉽게도 원데이터 모두를 사용할 수 없었다. 그래서 rating 데이터의 10만 케이스에 대해서 진행한 결과이다.
1. 사용자 기반 필터링의 경우 이해가 잘되서 구현하는데 어려움이 없었지만, 아이템 기반 필터링의 경우 헷갈렸다. 사용자 기반 필터링에서도 사용자 간의 유사도를 구할 때 특정 사용자와의 공통 항목이 있어야 했던 것처럼 아이템 간의 유사도를 구할 때 역시 공통으로 평가된 것을 토대로 계산한다.
두 필터링 간에는 뉘앙스가 조금 다르다. 단순히 사용자 간 유사도를 구하는 대신 아이템 간 유사도를 구해서 예측 평점을 구하는 것처럼 느껴지지만 실제로 구현을 해보니 차이를 알게 되었다.
사용자 기반 필터링은 나와 공통으로 평가한 항목을 가진 다른 사용자들과의 유사도를 토대로 그들이 내가 평가하지 않은 아이템들에 평가한 점수에 가중치를 주는 방식으로 내가 평가하지 않은 아이템 $i$들의 예측평점을 모두 구했다면,
아이템 기반 필터링은 내가 평가했던 아이템들의 점수의 가중 평균이다. 여기서 가중치가 아이템 간의 유사도일 뿐이다. 그 유사도는 $i$와 $j$가 동시에 평가됐을 때의 값들(벡터)으로 구한다.
2. 실제 도메인에서 저렇게 예측값들이 동일하게 많이 나온다면 사실상 의미가 없을지도 모른다. 사용자에게 추천할 수 있는 양은 완벽하게 통제되어 있고 한계가 있기마련이기 때문이다. 그렇기 때문에 도메인에 대한 관점을 알아야하고, 또한 더 다양한 기법들을 접목하여 보다 체계적으로 추천을 하면 좋을 것 같다.
아이템 기반에서 동시에 두 아이템을 평가한 사용자가 1명인 경우가 많다. 그럴때는 무조건 두 아이템간의 유사도는 1로 나타나게 되는데 이를 방지하기 위해서 저자는 5명 이상의 사용자에 의해 평가된 경우만 가지고 유사도를 구했다고 한다.
또한 사용자에 비해서 영화의 수가 많이 없다. 이러한 문제는 예측결과도 안좋게 만든다고 한다. 데이터 셋 자체의 sparsity 는 또 다른 기법들을 통해 성능을 올려보아야 한다.

조정된 코사인 유사도.
예를 들어 어떤 사람은 $a$영화에 2점 $b$영화에 4점을 주었다. 또 어떤 사람은 $a$영화에 1점 $b$영화에 2점을 주었다. 두 아이템의 유사도는 1이다. 두 영화는 육안으로 봐도 사뭇 받은 평점이 달라보이고 완벽하게 같다고 보이지는 않는다. 이에 조정된 코사인 유사도를 활용하면 각각 평균을 빼주게 되므로 각각 값이 척도를 반영할 수 있게 되어 위의 문제를 해결해 줄 수 있다.

'추천시스템' 카테고리의 다른 글
| surprise를 활용한 협업필터링(collaborative filtering) (3) | 2020.02.13 |
|---|---|
| 메모리 기반 하이브리드 필터링 구현 (0) | 2020.02.06 |
| 콘텐츠 기반 필터링 추천 예제 (0) | 2020.01.14 |
| 연구주제를 위한 논문 리뷰 (0) | 2020.01.10 |
| 사용자간 유사도를 활용한 협업필터링 추천 예제 (0) | 2019.11.24 |




댓글