협업필터링에는 메모리 기반, 모델 기반으로 또 나뉘어지게 되는데, 앞서 메모리 기반 협업필터링을 item-based와 user-based로 각각 연습한다. 이번에는 협업필터링을 파이썬에 surprise 라이브러리를 사용해서 item-based, user-based를 구현하고, 잠재 요인 모델(Latent Factor Models)도 실행해본다. Li 님[2]의 블로그를 보고 데이터는 movielens를 사용하여 몇가지 옵션만 달리해가며 따라해보았다.
우선 필요한 라이브러리와 데이터를 가져온다. 데이터는 계속 쓰던 movielens 데이터를 사용한다.
# 라이브러리 불러오기
import os
import pandas as pd
from surprise import Reader, Dataset
u.data.txt 데이터 공유 링크
drive.google.com/file/d/16KlDcbLYKG17hGzF5SIjIXV2HoHy4iwK/view?usp=sharing
# 데이터 불러오기
ratings=pd.read_csv("u.data.txt", sep='\t', header=None).head()
ratings.columns=['userId','movieId','rating','timestamp']
ratings.sort_values(by=['userId','movieId'], inplace=True)
ratings.head()

EDA
평점별로 분포를 막대그래프로 나타낸다. plotly 를 사용하여 그렸다. 단순하게 matplotlib.pyplot 을 사용해도 된다.
1. 평점의 분포(1,2,3,4,5)를 막대그래프로 살펴보기.
from plotly.offline import init_notebook_mode, plot, iplot
import plotly.graph_objs as go
# py파일로 실행할 경우 노트북에서 실행시키기 위한 함수.
# init_notebook_mode(connected=True)
# 데이터프레임에서 한 컬럼만 뽑아낸 시리즈를 종류별로 카운트하고, 인덱스에 따라 내림차순 정렬
data = ratings['rating'].value_counts().sort_index(ascending=False)
# x에는 index로 평점 1~5를 나타내고, y는 평점 당 카운트 값이다.
trace = go.Bar(x = data.index,
text = ['{:.1f} %'.format(val) for val in (data.values / ratings.shape[0] * 100)],
textposition = 'auto',
textfont = dict(color = '#000000'),
y = data.values,
)
# 레이아웃 생성하기.
layout = dict(title = 'Distribution Of {} movie-ratings'.format(ratings.shape[0]),
xaxis = dict(title = 'Rating'),
yaxis = dict(title = 'Count'))
# 그래프 생성하기
fig = go.Figure(data=[trace], layout=layout)
iplot(fig) 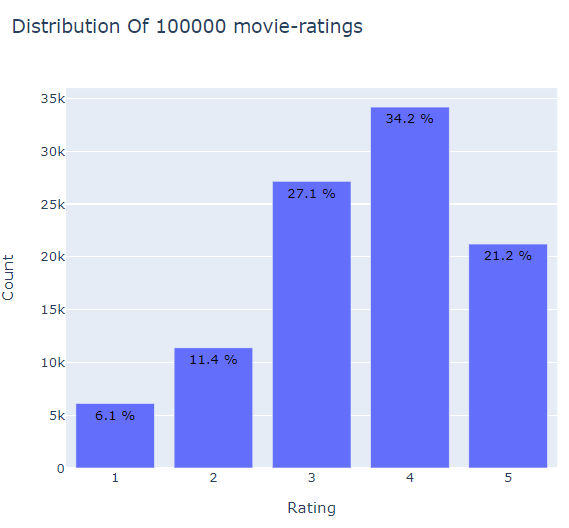
4점이 34.2%로 가장 많이 준 평점이 되겠다. 1점이 제일 적다. 평점 3이상이 80%가 넘는다. 3점이 보통이라 쳐도 4점 5점 합치면 55%로 반 이상이다. 긍정적인 사람들이라고 생각한다.
2. 영화 한편당 달린 평점의 개수 분포를 알아보기
# 영화 한 편당 평점 개수. groupby 함수로 카운팅한다.
data = ratings.groupby('movieId')['rating'].count().clip(upper=100)
# trace 생성하기.
trace = go.Histogram(x = data.values,
name = 'Ratings',
xbins = dict(start = 0,
end = 50,
size = 2))
# 레이아웃 생성하기
layout = go.Layout(title = 'Distribution Of Number of Ratings Per movie (Clipped at 100)',
xaxis = dict(title = 'Number of Ratings Per movie'),
yaxis = dict(title = 'Count'),
bargap = 0.2)
# 그래프 생성하기.
fig = go.Figure(data=[trace], layout=layout)
iplot(fig)
ratings.groupby('movieId')['rating'].count().reset_index().sort_values('rating', ascending=False)[:10]
히스토그램은 최대 개수를 100으로 제안하여 출력했는데 영화에 평점이 많이 달린 것은 538, 509, 508, 507, 485 개도 있다. 위 히스토그램에서는 141개가 1개의 평점을 지닌 것으로 나타났다. 뒤에 작업에서 다 짤라버린다.
히스토그램을 통해 거의 400개 정도가 평점이 5개 이하로 달렸다.
3. 사용자별 평점 개수 집계 히스토그램 그리기.
# 사용자별 평점 개수
data = ratings.groupby('userId')['rating'].count().clip(upper=50)
# trace 생성하기.
trace = go.Histogram(x = data.values,
name = 'Ratings',
xbins = dict(start = 0,
end = 50,
size = 2))
# 레이아웃 생성하기.
layout = go.Layout(title = 'Distribution Of Number of Ratings Per User (Clipped at 50)',
xaxis = dict(title = 'Ratings Per User'),
yaxis = dict(title = 'Count'),
bargap = 0.2)
# Create plot
fig = go.Figure(data=[trace], layout=layout)
iplot(fig)

#count()까지 Series타입이고, reset_index()까지 해서 dataframe이 된다.
ratings.groupby('userId')['rating'].count().reset_index().sort_values('rating',ascending=False)
사용자들은 최소 20개 이상을 평점을 준 사람들이고, 영화당 달린 평점 집계보다 전체적으로 고르게 퍼진 정도가 준수해보인다.
4. 메모리 에러를 방지하기 위해, 평점을 거의 안준 사용자, 평점을 거의 못받은 영화는 제거하는 작업.
평점을 거의 안준 사용자는 삭제하지 않는다, 최소 20개 이상 평점을 줬기 때문이다. 그러므로 평점을 거의 못받은 영화는 제거할 것이다. 영화는 평점이 5개 이상 달린거만 가져와 사용한다.(전에 읽은 논문에서 아이템 기반 협업필터링할 때, 뭐 한 5개 이상인거로 필터링한번하고 유사도를 구하고 했던 기억때문에 그렇게 함.)
min_movie_ratings = 5
filter_movies = ratings['movieId'].value_counts() >= min_movie_ratings
filter_movies = filter_movies[filter_movies].index.tolist()
ratings_new = ratings[ratings['movieId'].isin(filter_movies)]
print('The original data frame shape:\t{}'.format(ratings.shape))
print('The new data frame shape:\t{}'.format(ratings_new.shape))
별로 제거된 것이 없다.
print('(기존 영화 편수: ',len(set(ratings['movieId'])),')', ' - ', '(필터링 하고 영화 편수: ',len(set(ratings_new['movieId'])),')', ' = ',len(set(ratings['movieId'])) - len(set(ratings_new['movieId'])))
333개의 영화가 제거 되었다.
이제 surprise를 사용해보자.
Readera 클래스는 평점을 포함하는 파일을 분해해준다.
load_from_df() 는 pandas데이터 프레임으로부터 데이터셋을 로딩하기 위한 메소드이다.
앞에서 만든 Reader object를 사용하며, rating_scale을 명시해줘야하고, 데이터 프레임은 사용자id, 아이템id, 평가에 대응하는 3개의 컬럼을 가지고 있어야 한다.
surprise 라이브러리에서는 여러 알고리즘을 제공한다.
[3]에 자세한 설명이..
1. Basic 알고리즘.
:NormalPredictor 알고리즘은 노멀하다는 가정하에 트레이닝 셋 분포에 기반하여 랜덤 평점을 예측하는 알고리즘이다. 아주 기초적인 알고리즘중의 하나이며 많은 일은 하지 않는다.
:BaselineOnly 알고리즘은 사용자와 아이템에 대해 baseline 추정치를 예측한다.
2. K-NN 알고리즘.
:KNNBasic
:KNNWithMeans
:KNNWithZScore
:KNNBaseline
3. Matrix Factorization-based algorithms
:SVD 알고리즘은 Probabilistic Matrix Factorization과 관련이 있다.
:SVDpp 알고리즘은 SVD의 연장
:NMF 알고리즘은 SVD와 매우 유사하고, Non-negative matrix factorization(음수 미포함 행렬 분해)기반이다. .. 응?
:Slope One = straightforward implementation of the SlopeOne algorithm.
:Co-clustering = collaborative filtering algorithm based on co-clustering.
정확도 측정은 rmse 를 사용한다.
반복문을 통해서 모든 알고리즘에 대하여 평점예측을하고, 정확도를 산출한다.
from surprise import SVD, SVDpp, SlopeOne, NMF, NormalPredictor, KNNBasic, KNNBaseline, KNNWithMeans, KNNWithZScore, BaselineOnly, CoClustering
# from sklearn.model_selection import cross_validate 사이킷런의 크로스벨리데이션이 아니다.
from surprise.model_selection import cross_validate
benchmark = []
# 모든 알고리즘을 literate화 시켜서 반복문을 실행시킨다.
for algorithm in [SVD(), SVDpp(), SlopeOne(), NMF(), NormalPredictor(), KNNBaseline(), KNNBasic(), KNNWithMeans(), KNNWithZScore(), BaselineOnly(), CoClustering()]:
# 교차검증을 수행하는 단계.
results = cross_validate(algorithm, data, measures=['RMSE'], cv=3, verbose=False)
# 결과 저장과 알고리즘 이름 추가.
tmp = pd.DataFrame.from_dict(results).mean(axis=0)
tmp = tmp.append(pd.Series([str(algorithm).split(' ')[0].split('.')[-1]], index=['Algorithm']))
benchmark.append(tmp)
pd.DataFrame(benchmark).set_index('Algorithm').sort_values('test_rmse') 
뭐 이렇게 굉장히 깔끔하게 나온다. 여기서 봤을 때 가장 RMSE가 낮은 SVDpp를 선택하여 훈련을 시킨다. 훈련에는 경사하강법이랑 ALS(alternating least square) 방법이 있는데 ALS가 더 효과가 좋다고 한다. 훈련은 추후에 진행하도록 함.
reference:
[1]
surprise 라이브러리를 이용한 협업필터링(Collaborative Filtering) 파이썬 치트코드 – Go Lab
협업필터링은 일반적인 memory(user, item) based 그리고 머신러닝을 이용해서 예측을 하는 model based의 필터링, 그리고 거기에 더해 희소행렬을 아예 임베딩등을 통해 차원을 변경해 여러 레이어로 구성된 딥러닝 필터링까지도 가능하다. 여기서는, surprise라이브러리로 구현이 가능함을 보인다.
machinelearningkorea.com
[2]
Building and Testing Recommender Systems With Surprise, Step-By-Step
Learn how to build your own recommendation engine with the help of Python and Surprise Library, Collaborative Filtering
towardsdatascience.com
[3]
https://surprise.readthedocs.io/en/stable/basic_algorithms.html
Basic algorithms — Surprise 1 documentation
© Copyright 2015, Nicolas Hug Revision f98907f8.
surprise.readthedocs.io
포스팅에 사용한 jupyter notebook 작업 파일.
drive.google.com/file/d/13m6bpmkK3VtVrbJ7wNO_9jUfsNEk7_jr/view?usp=sharing
'추천시스템' 카테고리의 다른 글
| 메모리 기반 CF 추천시스템의 문제점 (0) | 2020.08.23 |
|---|---|
| SVD 를 활용한 협업필터링 (4) | 2020.02.22 |
| 메모리 기반 하이브리드 필터링 구현 (0) | 2020.02.06 |
| MovieLens 데이터를 활용한 Collaborative Filtering 구현 (0) | 2020.01.15 |
| 콘텐츠 기반 필터링 추천 예제 (0) | 2020.01.14 |



댓글