알고리즘 중에서 가능한 모든 데이터를 다 탐색해야 하는 문제를 해결할 때, 효율적으로 탐색하기 위한 알고리즘이 BFS(Breath-first search), DFS(Depth-first search) 이다.
BFS는 Breath 가 의미하는 것처럼 넒게 보면서 탐색해나가는 것이고, DFS는 Depth가 의미하는 것처럼 하나를 끝까지 탐색한 후 직전으로 돌아와 다시 끝까지 탐색해 나간다라고 우선 받아들여보자..
우선 쉬운 예제를 통해서 어떤 것을 하고 싶은건지 알아보도록 하자.
먼저 DFS에 대해서 살펴보자.

기본적으로 주어지는 데이터의 형태는 각양각색이다. 그래서 어떻게 위의 그림처럼 네트워크의 형태로 꾸리는 것이 가장 먼저 할 일이다.
아래의 코드에서 network1, network2 는 위의 그림에서 한 노드가 어디랑 연결되어 있는지를 간단하게 표현한 구조이다. network1 같은 경우는 딕셔너리 형태이고 key 값이 곧 위 그림의 노드가 될 것이고, value는 해당 노드에서 연결된 다른 노드를 나타낸다. network2 같은 경우에는 array의 형태로 나타냈는데 자기 자신 또는 자신과 연결된 다른 노드에 해당하는 곳에 1로 표시한다. network1 의 key 순서대로 하나의 노드라고 생각하면 된다.
import numpy as np
network1 = {
'A':['B','C','D'],
'B':['A','E','F'],
'C':['A','G'],
'D':['A','H'],
'E':['B'],
'F':['B','I','J'],
'G':['C'],
'H':['D'],
'I':['F'],
'J':['F']
}
network2 = np.array(
[
# A B C D E F G H I J
[1,1,1,1,0,0,0,0,0,0], # -> node 'A'
[1,1,0,0,1,0,0,1,0,0], # -> node 'B'
[1,0,1,0,0,0,1,0,0,0], # -> node 'C'
[1,0,0,1,0,0,0,1,0,0], # -> node 'D'
[0,1,0,0,1,0,0,0,0,0], # -> node 'E'
[0,1,0,0,0,1,0,0,1,1], # -> node 'F'
[0,0,1,0,0,0,1,0,0,0], # -> node 'G'
[0,0,0,1,0,0,0,1,0,0], # -> node 'H'
[0,0,0,0,0,1,0,0,1,0], # -> node 'I'
[0,0,0,0,0,1,0,0,0,1] # -> node 'J'
]
)
network1와 같은 형태로 주어지거나 혹은 우리가 이렇게 꾸렸다고 치고, 아래의 코드로 DFS를 구현한다.
먼저 가장 먼저 어떤 노드에서 시작하는지를 지정해준다. 아래의 코드에서는 parent_node로 'A' 를 지정해 준 것을 볼 수 있다.
그리고 place라는 리스트 변수를 하나 만든다. place의 역할은 우리가 탐색해야할 장소를 저장하는 곳이라고 할 수 있다. 즉 key에 해당하는 value를 저장해주는 곳이다. 리스트 end의 역할은 우리가 이미 탐색한 장소를 저장하는 곳이다. 그래서 다시 반복해서 접근하지 않게 해준다.
먼저 place에 'A' 를 넣어주게 된다. 그리고 'A'는 key가 되고 해당 value인 'D','C','B'가 place에 담긴다. 이 때 한 번 key가 되었으면 end 리스트에 넣어준다. end 리스트는 아래의 그림에서 왼쪽 위에서 두번째 항아리에서 'D'를 key로 사용할 때 이미 갔던 'A'에 다시 가지 않기 위해서 사용된다. 코드에서는 if 문이 그러하다. 처음 두세번정도 과정을 이해하면 계속 반복이다. place에 append하고 pop을 하는 과정이 stack 자료구조를 연상케 한다.
이렇게 반복을 하면서 탐색을 하되 만약 문제가 특정 노드를 찾는 것이라면 if 문을 추가하면 된다.
parent_node = 'A'
place = [parent_node]
end = []
while place:
now = place.pop()
end.append(now)
for i in network1[now]:
if i not in end:
place.append(i)
다음으로 BFS에 대해서 살펴보자.
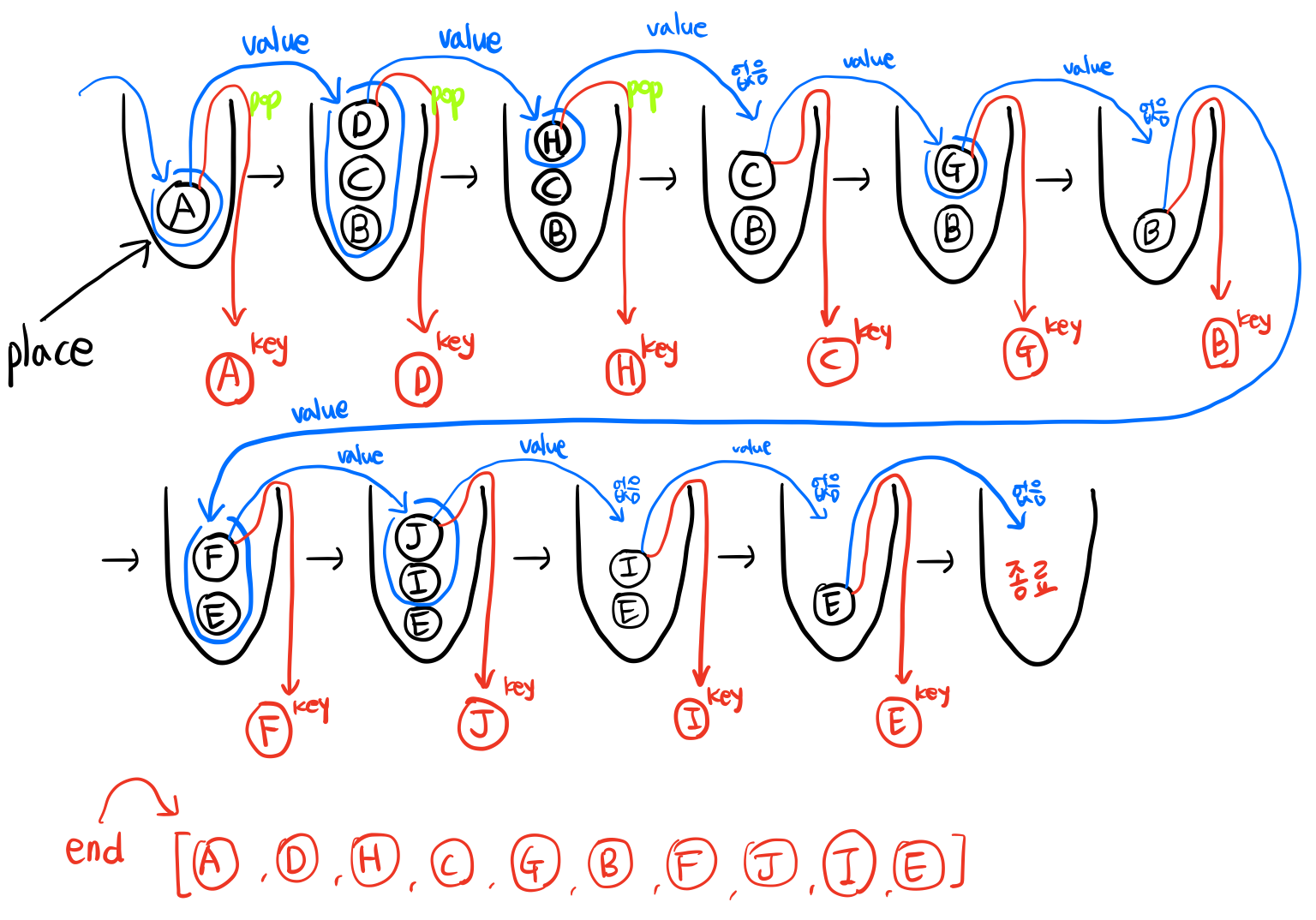
개인적으로 DFS는 구현함에 있어 BFS보다 더 직관적으로 와닿았다. 하지만 모든 노드를 탐색하는 알고리즘이라는 점을 동일하며, 차이라고 한다면 위에서 stack 의 개념으로 place에 추가하고 pop을 했다면 BFS는 stack 처럼 마지막에 넣은 것을 바로 key로 사용하는 것이 아닌 가장 먼저 들어가있던 node를 key로 사용하는 차이다.

아래의 코드를 보면 pop()에 0 이 들어가 있는 것을 알 수 있다. 먼저 들어간 것부터 빼주는 것을 의미하며, 이 0이 있고 없고가 BFS, DFS의 차이의 전부이다.
parent_node = 'A'
place = [parent_node]
end = []
while place:
now = place.pop(0)
end.append(now)
for i in network1[now]:
if i not in end:
place.append(i)아래의 그림을 DFS랑 비교해보면 key로 넣던 빨간색 동그라미 부분이 가장 아래에 있는(먼저 들어간) 노드를 key로 사용해나가는 것을 알 수 있다. 아래의 end에 노드가 쌓이는 순서를 보면 DFS와의 차이를 확인해볼 수 있다.

fef)
'파이썬 알고리즘 코딩' 카테고리의 다른 글
| 유효한 펠린드롬 문제 (0) | 2021.03.28 |
|---|---|
| 프로그래머스 Lv3 여행경로 (0) | 2021.03.13 |
| N으로 표현 (프로그래머스 Lv3 동적프로그래밍) (0) | 2021.01.25 |
| 가장 큰 수(프로그래머스 level2) (0) | 2021.01.21 |
| 쿼드압축 후 개수 세기 (프로그래머스 level2) (0) | 2020.11.04 |


댓글