먼저, 파이토치의 기본 단위인 텐서에 대하여 알아보자. 파이토치는 GPU 단위의 연산을 가능하게 하고, numpy 의 배열과 유사해서 손쉽게 다룰 수 있다. 파이토치를 사용하기 위해 import torch 를 통해 torch 라이브러리를 불러온다.
파이토치는 ones, zeros, rand 와같이 nupmy 에서 자주 사용하던 함수들을 손쉽게 사용할 수 있다.
import torch
import numpy as np위와 같이 라이브러리를 불러온다. 그런 다음 아래와 같이 비어있는 텐서를 생성해보자.
아래의 텐서는 5 x 4 짜리 행렬을 의미한다.
x = torch.empty(5,4)
x
아래의 ones, zeros, rand 함수를 이용해서 각각 구현한 것은 아래와 같다.
torch.ones(3,3)
torch.zeros(3,3)
torch.rand(5,6) # 표준정규 분포 기준.
그다음 list 나 array 를 텐서로 바꾸어 줄 수 있다.
l = [1,2,3]
a = [[1,2,3],[4,5,6]]
print(torch.tensor(l))
print(torch.tensor(a))
텐서의 크기와 타입을 확인하는 일은 자주 사용이 된다. 아래와 같이 손쉽게 확인이 가능하다.
x.size()
type(x)
텐서의 덧셈에 대해서 살펴보자.
x = torch.ones(2,2)
x
x.add(x)
torch.add(x,x)
다양한 방식으로 덧셈이 가능한데, 특히 add_ 의 경우는 inplace=True 할 때처럼 덮어씌우는 식으로 연산이 수행이 된다. 그리고 간단하게 x+x 를 했을 때, inplace 된 x 들의 덧셈으로 결과가 나온 것을 알 수 있다.
x.add_(x)x+x
텐서의 크기를 변환하는 일은 많이 사용한다.
예컨데 CNN 에서 Conv layer에서 fully connect 로 갈 때, flatten 을 하는 과정이 있는데, 그런데 사용이 된다. torch.rand로 8x8 짜리 텐서를 만들고, view 함수를 사용해서 텐서의 size 를 변형시켜보도록 하자.
x = torch.rand(8,8)
print(x.size())
a = x.view(64)
print(a.size())
위의 a 와 같은 경우는 기존의 8 x 8 텐서를 64 x 1 의 벡터 형태로 바꿔준 것이라 할 수 있다.
위의 예시는 1차원으로 바꿔준건데, 3차원으로 바꾸고 싶을 때는 view 함수에 3개의 값을 입력해주면 된다.
아래의 예시에서 b를 만들어주는 과정이 그렇다.
보면 -1,4,4 가 되어 있는데, 8x8 텐서는 원소가 64개가 존재할텐데 1차원이 4, 2차원이 4로 지정을 했다면, 모든 원소를 표현하려면 이러한 4x4 텐서가 4개더 존재해야한다.
즉, 모든 원소를 다 표현하기 위해서 하나는 -1로 하여 알아서 표현하게끔 해주는 것이다. 여기서 -1,4,4 는 4,4,4 와 같은 의미로 사용된다고 보면 된다.
b = x.view(-1,4,4)
print(b.size())
b
x
위의 3차원의 텐서로 변형한 b 와 기존의 x 를 비교해서 어떤식으로 쪼개어 졌는지 확인할 수 있다. 행단위 벡터들의 순서대로 차례로 좌상우하 방향으로 새로운 텐서에 입력이 되는 것을 확인할 수 있다.
단일 텐서에서 값을 뽑아내는 것에 대해 살펴보자.
x = torch.ones(1)
x
x.item()

위와 같이 단일 텐서의 경우에는 손실함수와 같은 스칼라 값으로 표현이 되는데, 텐서 타입이 의미가 없다. 그래서 스칼라로 뽑아주기 위해서 사용이 된다.
이 item() 은 단일 숫자인 경우에만 사용이 가능하다.
NN에서 최적화과정에 필수적인 요소인 미분을 특히 backpropagation 을 쉽게 할 수 있도록 pytorch는 자동 미분 기능을 제공하고 있다.
먼저 자동 미분을 하기 위한 준비를 한다.
아래의 ones 는 전에 배웠고, 그 속에 매개변수로 requires_grad=True 라는 것은 이 x 가 미분이 가능하도록저 자동 미분을 하기 위한 준비를 한다.
import torch
x = torch.ones(2,2, requires_grad=True)
print(x)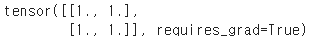
아래의 y 는 x를 입력으로 받는 함수, z 는 y 를 입력으로 받는 함수라고 생각하면 된다. res도 역시 z에 대한 식이다.
출력값에 grad_fn= ... 이 있는데 이것은 역전파의 방향을 나타내니 곧 추적이 잘 되고 있는 상태를 나타낸다.
y = x + 1
z = 2*y**2
res = z.mean()
print(y)
print(z)
print(res)
역전파는 어떻게 구현할까.
예측값이 나오면 그 예측값과 실제값의 차이로 손실함수를 구성하고, 그리고 역전파 알고리즘을 통해서 가중치를 업데이트 해나가는데, 이과정에서 우리는 loss를 최초 입력에 대한 미분과정을 거친다.
추적과정은 위의 함수x, y, z, res 에 대해 알아서 잘 추적이 되어 있는 상태이므로 res에 대해서 미분을 진행하면 아래와 같다.
res.backward() # res를 기준으로 역전파를 진행.
각 함수 x, y, z, re를 아래와 같이 표현해볼 수 있다.
$res = \frac{(z_{1}, ..., z_{4})}{4}$
$z = 2 \cdot (y_{1}, ... ,y_{4})^{2}$
$z = 2 \cdot (x_{1}+1, ... ,x_{4}+1)^{2}$
$\frac{\partial \ red}{\partial \ x_{i}} = x_{i} + 1$

print(x)
print(x.grad)
위의 코드 x.grad 는 backward()가 선언된 변수를 기준으로 미분을 한다. 위에서 res를 backward()로 선언을 했는데, 이 때 res를 기준으로 x에 대한 미분값인 $\frac{\partial \ res}{\partial \ x}$를 계산한다고 할 수 있다.
일일히 gradient 를 직접 구해야하는 경우도 있는데 일반적으로는 backward()와 optimizer를 사용해서 직접 gradient를 구할 일은 초반에는 잘 없다.
정리해보면 여기서는 자동미분을 활용한 역전파를 위해서는 먼저 requires_grad=True로 기준을 잡고 연쇄법칙을 활용해서 backward를 진행하는 개념을 넣어 두도록 하자.
이번에는 파이토치에서 주어지는 데이터셋을 불러오는 작업을 해본다.
라이브러리 중 torchvision 은 이미지 관련 라이브러리이며, torchvision의 transforms는 이미지 데이터의 전처리 기능을 제공한다.
pytorch.utils.data의 DataLoader, Dataset은 데이터를 모델에 사용할 수 있게 텐서의 타입을 설정하는 등의 다듬어 줄 수 있는 기능을 포함한다.
import torch
import torchvision
import torchvision.transforms as tr
from torch.utils.data import DataLoader, Dataset
import numpy as nptr.Compose를 통해 데이터를 어떻게 불러오고 가공을 할 지 미리 정의해준다.
transf = tr.Compose([tr.Resize(16), tr.ToTensor()]) # 16 x 16 사이즈로 이미지 크기를 변환하고 텐서타입으로 변환한다.
Padding이나 greyscale로 바꿔주는거나 이미지의 일부를 잘라서 학습시키는 RandomCrop방법, Normalize 등 다양한 방법이 있다.
이러한 방법들을 Compose 안에 넣어 커스터마이징 해줄 수 있다. Compose 안에 넣어주는 것은 차례로 연산을 시켜주는 묶음이라고 생각하면 된다.
https://pytorch.org/vision/stable/transforms.html
위 사이트에서 Compose 사용법이 설명되어 있는데, torch.nn.Sequential 를 사용하라고 한다.
https://pytorch.org/vision/stable/datasets.html
위 사이트는 파이토치에서 불러올 수 있는 데이터 셋들에 대한 내용이 담긴 페이지이다. 이미지 데이터들이 즐비해있다.
여기서는 CIFAR10 이라는 10개의 클래스를 가진 이미지 데이터를 가져와본다.
root 는 다운받은 파일이 들어갈 경로를 말하고, train이 True 이면 train set 을 불러오고, False 면 test set을 불러온다. download는 다운받는다는 의미이고, transform은 전처리 방법을 넣어주는건데 위에서 설정한대로 resize하고 tesnsor로 바꿔주는 역할을 한다.
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transf)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transf)
일반적으로 데이터셋은 이미지와 라벨이 동시에 들어있는 튜플형태이다. 예를 들어 (이미지, 라벨) 과 같은 형태이다.
아래의 trainset[0] 은 불러온 데이터의 첫번째 데이터이며 튜플안에 이미지를 표현한 텐서와 그리고 두번째 라벨이 있는 것을 확인할 수 있다. 얘는 label 이 6이다..

중략 ...

trainset[0][0].size()
하나의 데이터의 이미지는 3 x 16 x 16 으로 구성되어 있다.
이말인즉슨 텐서가 3이니 RGB 형태의 컬러 이미지이며, width와 height가 각각 16이라는 것을 알 수 있다. 쉽게 말해 16x16행렬이 3개!
파이토치는 다른 툴과 다르다. (채널수) x (너비) x (높이) 형태로 되어 있음에 유의하도록 하자.
이제 DataLoader 를 사용해서 데이터셋의 배치사이즈를 정해준다. 즉, 미니 배치 형태로 만들어 주는 것이며 셔플을 할건지에 대한 옵션 설정을 해준다.
아래의 배치사이즈 50은 한번 학습을 할 때마다 이미지가 50개씩 들어가서 학습을 한다는 얘기이다. shuffle 은 학습때마다 학습에 참여할 데이터를 랜덤하게 뽑는다는 의미이다.
testset은 학습을 안하기때문에 배치사이즈 설정이 필요없으나 많이 들어가면 메모리 문제가 발생하기에 일반적으로 배치로 계산을 하게 해준다.
trainloader = DataLoader(trainset, batch_size=50, shuffle=True)
testloader = DataLoader(testset, batch_size=50, shuffle=False)CIFAR 데이터셋은 이미지가 50,000 장이다. 그런데 배치사이즈를 50으로 했으니 배치의 개수는 1,000개가 된다. 즉 배치당 1,000개의 이미지가 묶여 있는 것이다.
아래를 확인해보면 1,000개의 배치가 출력된 것을 확인할 수 있다.
len(trainloader)
데이터가 잘 들어왔는지 확인을 해보자. 데이터를 하나씩 확인해볼 때 iter 함수를 사용한다.
next 함수를 사용해서 첫번째 데이터를 뽑는데, 확인을 해보니 3 x 16 x 16 짜리 이미지가 50 장이 들어있는 것을 확인할 수 있다.
dataiter = iter(trainloader)
images, labels = dataiter.next()
print(images.size()) # (배치크기) x (채널수) x (너비) x (높이)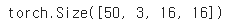
이미지 데이터를 불러와보자. 파이토치에서는 따로 라벨링을 해주지 않을수도 있다. 왜냐하면 애초에 우리가 이미지를 label 별로 로컬 디렉토리의 폴더에 넣어두면 되기 때문이다.
현재 공부를 하는 환경이 코랩이다 보니 코랩을 사용해서 따라해보도록 하자아.
데이터는 드라이브에 있으니 코랩에 드라이브를 마운트 시키고 불러와보자. 마운트시키는 것은 코드 입력 후 구글이 시키는 대로 하면 된다.
from google.colab import drive
drive.mount('/content/gdrive')
마운트를 했으면, 디렉토리를 변경해주자. 리눅스 명령어 change directory를 사용해서 현재 위치로 바꿔주자.
My Drive는 드라이브 딱 켰을 때 그 때의 디렉토리 주소이다. 이 후 내가 불러온 데이터가 있는 경로로 설정해주자.
cd/content/gdrive/My Drive/deeplearningbro/pytorch
transf = tr.Compose([tr.Resize(128), tr.ToTensor()]) # 128x128 이미지 크기로 변환하고 tensor로 변환한다.
trainset = torchvision.datasets.ImageFolder(root='./class', transform=transf) # cd로 전환한 현재 디렉토리에 class라는 폴더가 있기에 그곳에서 불러오게 한다.
trainloader = DataLoader(trainset, batch_size=1, shuffle=False) # 데이터를 미니 배치 형태로 만들어 준다.위 처럼 ImageFolder 를 사용하는 경우에는 라벨별로 폴더에 깔끔하게 정리가 되어 있어야 한다.
정형화가 되어 있지 않은 커스텀 데이터를 불러오는 경우에는 어떨까?
현실에선 라벨별로 폴더에 정리가 되어 있지 않은 경우나 이미지 데이터인데 이미지가 아닌 텍스트, 리스트, 배열등의 형태로 저장되어 있는 경우가 존재하기 때문이다.
우선 32 x 32 컬러 이미지와 라벨이 각각 100장이 있다고 가정하고 아래의 코드를 보자. np.random.randint(256) 은 0 ~ 255 까지의 정수를 랜덤하게 뽑는 역할이다. size 를 설정하면 size 만큼 랜덤하게 샘플링을 한다.
label 은 0,1 두가지 클래스로 설정하였다.
train_images = np.random.randint(256, size=(100,32,32,3)) # (이미지수) x (너비) x (높이) x (채널수)
train_labels = np.random.randint(2, size=(100,1)) # 라벨 수
이미지 전처리 작업은 OpenCV 나 SciPy와 같은 더 다양한 전처리 작업을 도와주는 라이브러리들이 존재한다.
이 부분에서 전처리 작업을 하고 이후에 텐서를 구성하길 추천한다. 물론 torchvision.transforms 를 사용해도 된다.
전처리를 다루지는 않기 때문에 일단 아래의 코드의 preprocessing 처럼 어떤 전처리를 우리가 해줬다고 가정하자.
# train_images, train_labels = preprocessing(train_images, train_labels)
# 전처리가 위의 코드처럼 이루어 졌다라고 가정한다면, 아래처럼 형태에 맞추어 잘 나오게 된다.그렇게 전처리를 해주고 나서 출력을 해주면 아래와 같은 형태로 출력이 된다.
print(train_images.shape, train_labels.shape)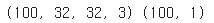
이제 데이터를 사용할 수 있게끔 텐서데이터로 바꿔줘야 한다.
"""
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self):
def __getitem__(self, index):
def __len__(self):
"""위와 같이와 같이 데이터를 텐서 데이터로 바꿔주는 양식을 잘 가지고 다니기를 추천한다.
기본값들이 init에서 작성이 되고, 실제 나가는 데이터를 getitem로부터 적어주고, len은 데이터 개수를 나타낸다.
class TensorData(Dataset):
def __init__(self, x_data, y_data):
self.x_data = torch.FloatTensor(x_data) # 이미지 데이터를 FloatTensor로 변형.(tensor의 숫자 type)
self.x_data = self.x_data.permute(0,3,1,2) # (이미지 수) x (너비) x (높이) x (채널 수) ---> (배치크기) x (채널 수) x (너비) x (높이)
self.y_data = torch.LongTensor(y_data) # 라벨 데이터를 LongTensor로 변형.
self.len = self.y_data.shape[0] # 클래스 내의 들어온 데이터 개수.
def __getitem__(self, index):
return self.x_data[index], self.y_data[index] # 뽑아낼 데이터를 적어준다.
def __len__(self):
return self.len # 클래스 내의 들어온 데이터 개수.클래스 TensorData 안에 Dataset이 존재하는데 Dataset 은 파이토치에서 제공하는 클래스 Dataset이 가진 모든 기능을 다 사용할 수 있게 한다. 이것이 상속이라는 것이다. 상속받으면 Dataset의 기능을 TensorData안에 넣어주는 것이다.
permute는 각 차원의 위치를 바꿔주는 역할을 한다. 여기서 (0,3,1,2) 가 왜나왔냐하면 train_images 는 파이토치에서 원하는 형태의 차원으로 나열이 되어있지 않기 때문이다. 바꿔준다.
아래의 코드로 모델에 투입될 데이터셋이 최종적으로 구성되게 된다. ("나중에 예시를 통해 보면 더 잘 이해가 될 것 같다.")
train_data = TensorData(train_images, train_labels) # train 데이터를 불러와주고,
train_loader = DataLoader(train_data, batch_size=10, shuffle=True) # # 배치 형태로 만들어 주자.
정리를 해보면
1. train_images, train_labels 와 같은 데이터를 불러온다. 이 때 train_images, train_labels 는 전처리를 한 상태이다.
2. TensorData 를 통해서 데이터의 tensor type 을 설정해준다.
3. DataLoader 를 통해서 데이터셋의 배치사이즈를 정해준다.
머신러닝에서 데이터를 잘 불러오고 전처리를 잘 하는 것은 매우 중요하다는 사실은 익히 알려져 있다.
이번에는 조금 더 심화된 형태의 데이터를 불러오는 법을 배운당.
import torch
import torchvision.transforms as tr # 이미지 전처리 기능을 제공하는 라이브러리
from torch.utils.data import DataLoader, Dataset # 데이터를 모델에 사용할 수 있도록 정리해 주는 라이브러리
import numpy as np
외부로부터 데이터를 받아오는 방법은 다양하다.
glob를 라이브러리를 이용해서 경로에 대한 내용을 받아서 PIL로 받아올수있고, OpenCV로도 받아올 수 있다.
train_images = np.random.randint(256, size=(100,32,32,3)) # (이미지 수) x (너비) x (높이) x (채널 수)
train_labels = np.random.randint(2,size=(100,1)) # 라벨 수
위에서 사용한 양식을 아래에서 그대로 사용한다. 여기에 transform 을 넣어주게 된다.
그래서 커스텀 데이터를 어떻게 전처리하는지 보자.
앞전에는 TensorData라는 클래스를 통해서 tensor를 구축하기 전에! 전처리를 먼저 해준 후에 클래스 TensorData를 사용했는데, 이번에는 클래스에서 텐서를 만들면서 transform을 해보도록 하자.
class MyDataset(Dataset):
def __init__(self, x_data, y_data, transform=None):
self.x_data = x_data
self.y_data = y_data
self.transform = transform
self.len = len(y_data)
def __getitem__(self, index):
sample = self.x_data[index], self.y_data[index]
if self.transform:
sample = self.transform(sample)
return sample # 이전에 봤던 것과 다르게 numpy array로 출력됨에 유의하자
def __len__(self):
return self.len # 클래스 내의 들어온 데이터 개수.
전처리 기술을 직접 만든다. 위의 기본 양식과 같이 사용하기 위해서 call 함수를 사용한다. call 함수 내에서 전처리 작업을 할 수 있다.
#1. 텐서 변환
class ToTensor:
def __call__(self, sample):
inputs, labels = sample
inputs = torch.FloatTensor(inputs) # 텐서로 변환한다.
inputs = inputs.permute(2,0,1) # 파이토치 형식에 맞게 크기를 변환한다. # call 함수는 한 장씩 불러와서 (2,0,1)로 표현하였다.
return inputs, torch.LongTensor(labels) # 텐서로 변환한다.
#2. 선형식
class LinearTensor:
def __init__(self, slope=1, bias=0): # a, b는 외부로 받아야하기 때문에 초깃값을 받는 init.
self.slope = slope
self.bias = bias
def __call__(self, sample):
inputs, labels = sample
inputs = self.slope * inputs + self.bias # ax+b 계산하기.
return inputs, labels
# 여기에 추가로 계속 전처리 작업을 더해줄 수 있음.trans = tr.Compose([ToTensor(), LinearTensor(2,5)]) # 텐서 변환 후 선형식 2x+5 연산.
dataset1 = MyDataset(train_images, train_labels, transform=trans)
train_loader1 = DataLoader(dataset1, batch_size=10, shuffle=True)위 코드에서 ToTensor는 tr.ToTensor 와는 다르다. tr이 붙은건 라이브러리에 있는걸 사용한 것이고 tr 이 없는것은 직접 만든 텐서 변환클래스를 사용한다는 것이다.
dataiter1 = iter(train_loader1)
images1, labels1 = dataiter1.next()
print(images1.size())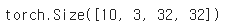
10개의 배치에 3개의 채널, 그리고 너비와 높이가 각각 32인 텐서로 잘 뽑힌걸 확인할 수 있다.
제공하는 transforms를 사용해서 전처리를 해보도록 하자.
torchvision.transforms에서 제공하는 전처리 기술을 사용한다. 파이토치는 입력 이미지가 일반적으로 PILImage 타입이나 텐서일 경우에만 동작한다.
현재 데이터는 numpy의 array 형태이다. 그래서 텐서 변환을 했다면 tr.Compose에서 tr.ToPILImage()을 이용해서 PILImage 타입으로 만들어 주도록 한다. 그리고 Resize 해주고, tensor 변환해주고, normalize 를 죽 해준다.
tr.Compose 안에 tr. tr. tr. tr. 즉 파이토치에서 제공하는 함수들을 사용하였다는 것을 확인이 가능하다.
__call__ 의 기본구조는 동일하다.
class MyTransform:
def __call__(self, sample):
inputs, labels = sample
inputs = torch.FloatTensor(inputs)
inputs = inputs.permute(2,0,1)
labels = torch.FloatTensor(labels)
# 파이토치에서는 PILImage 타입이나 텐서일때만 동작을 해서 첫빵에 tr.ToPILImage()를 박아준다.
transf = tr.Compose([tr.ToPILImage(), tr.Resize(128), tr.ToTensor(), tr.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))]) # 파이토치에서 제공하는 함수들을 다사용하였다. tr.tr.tr.tr.
final_output = transf(inputs)
return final_output, labels
dataset2 = MyDataset(train_images, train_labels, transform=MyTransform())
train_loader2 = DataLoader(dataset2, batch_size=15, shuffle = True)dataiter2 = iter(train_loader2)
images2, labels2 = dataiter2.next()
print(images2.size()) 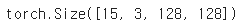
배치 15개, 채널 수 3개 너비와 높이 128로 잘 구성이 되어있는 것을 확인할 수 있다.
ref) deeplearningbro
https://pytorch.org/vision/stable/transforms.html
https://pytorch.org/vision/stable/datasets.html
'딥러닝' 카테고리의 다른 글
| Pytorch로 구현하는 CNN(Convolutional Neural Network) (0) | 2021.04.14 |
|---|---|
| Pytorch로 구현하는 Multi-Layer Perceptron (0) | 2021.04.13 |
| RNN (0) | 2021.04.10 |
| Activation Function (0) | 2020.09.24 |
| multi-layer perceptron (0) | 2020.08.27 |




댓글