CNN 을 파이토치로 구현을 하는 코드이다. CNN 은 이미지 처리에 강력하다. 멀티프로세싱에 유리한 GPU 연산으로 사용한다. 구글 코랩으로 사용한다.
먼저 라이브러리들을 불러오도록 한다.
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt미리 코랩에 드라이브 디렉토리를 마운트 시켜 준다.
from google.colab import drive
drive.mount('/content/gdrive')경로 설정도 해준다.
cd/content/gdrive/My Drive/deeplearningbro/pytorch
여기서는 CIFAR10 의 데이터셋을 사용한다. 클래스 10개의 이미지를 가지는 데이터이다. 3d tensor로 구성되어 있다.
클래스에는 'plane','car','bird','cat','deer','dog','frog','horse','ship','truck' 이 있다.
전처리를 위해서 Compose로 셋팅해준다. 여기선 tensor 데이터로 바꿔주는 거랑 normalize하는 전처리만 한다. 추가적으로 더 넣어도 된다.
Normalize 내부에는 평균과 표준편차로 구성된 것이다. 3개씩 인것은 데이터가 color데이터기 때문에 3차원(channel*width*height)이기 때문에 그렇다. 0.5는 임의로 설정한 것이다. 데이터의 최적의 평균, 표준편차를 구해 넣어주는게 더 좋을 수 있다.
CIFAR10 데이터셋은 파이토치에서 제공을 해주기 때문에 쉽게 다운받을 수 있다. 불러올 때는 transforms를 이용해서 전처리를 해준다.
DataLoader로 배치 형태로 만들어 준다.
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))]
)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=8, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=8, shuffle=False)


device를 설정해서 GPU 연산을 가능하게 해주는 CUDA를 사용하자. cpu라고 뜨면 코랩이면 런타임에서 gpu로 설정을 바꿔준다.
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(f'{device} is available')
이제 CNN 모델을 구축해보자. Conv와 pooling을 사용하였다.
nn.Conv2d(3, 6, 5) 가 의미하는 것은 일단 들어오는 입력 채널의 수가 3개이다. 칼라 이미지이기 때문이다. 그리고 출력 채널 수는 사용자가 정해줄 수 있는 부분이다.
그래서 여기서는 6개의 채널로 출력을 시켰다. 그리고 window size는 5x5로 슬라이딩을 진행한다. window가 움직이는 크기를 나타내는 stride는 디폴트는 1칸이다. 여기선 하지 않았지만 padding도 설정이 가능하다.
convolutional 연산이 끝나면 다음으로 maxplooling에 들어간다. nn.MaxPool2d(2,2)는 2x2짜리 필터를 사용한다는 것이다.
conv와 pooling이 끝나면 nn.Linear(16 * 5 * 5, 120)을 통해 피쳐맵을 일렬로 편다. 일렬로 폈을 때 16 * 5 * 5 노드, 즉 이걸 입력벡터로 해서 120개의 히든노드를 가진 히든레이어를 하나 만든다.
그런다음 nn.Linear(120, 10) 히든노드 120개에서 출력층에는 10가지 클래스를 구분하는 문제니까 10개의 노드로 최종적으로 출력이 되게 한다.
forward내에서의 연산은 conv1 -> relu -> pooling -> conv2 -> relu -> polling -> linear -> output
.view 로 일렬인 노드로 만드는데, -1은 배치수 만큼 만들어야하니까 지정을 해준 것이다.
.to(device)를 통해 GPU 연산을 할 수 있게 하여 선언한다.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 합성곱 연산 (입력 채널 수: 3, 출력 채널 수: 6, 필터 크기: 5x5, stride=1(default))
self.pool1 = nn.MaxPool2d(2,2) # 합성곱 연산 (필터크기 2x2, stride=2)
self.conv2 = nn.Conv2d(6, 16, 5) # 합성곱 연산 (입력 채널 수: 6, 출력 채널수: 16, 필터 크기: 5x5, stride=1(default))
self.pool2 = nn.MaxPool2d(2, 2) # 합성곱 연산 (필터크기 2x2, stride=2)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 피쳐맵 16개를 일렬로 피면 16*5*5개의 노드가 생성됨.
self.fc2 = nn.Linear(120, 10)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x))) # conv1 -> ReLU -> pool1
x = self.pool2(F.relu(self.conv2(x))) # conv2 -> ReLU -> pool2
x = x.view(-1, 16 * 5 * 5) # 5x5 피쳐맵 16개를 일렬로 만든다.
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return x
net = Net().to(device) # 모델 선언print(net)
# 피쳐맵은 다음과 같이 바뀌면서 진행된다. 32 -> 28 -> 14 -> 14 -> 5 
분류문제이기 때문에 손실함수를 크로스 엔트로피를 사용한다.
위에서 class Net()으로 정의한 파라미터를 net.parameters()로 설정해준다. 그리고 최적화 방법으로는 모멘텀을 활용한다.
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=1e-3, momentum=0.9)학습하는 과정은 이전에 MLP에서 했던 것과 동일하게 진행한다.
gpu를 연산을 하려면 gpu용 모델이 있어야하고 gpu용 데이터가 있어야 한다. 그래서 data 뒤에 .to(device)를 붙여서 gpu연산이 가능한 tensor데이터 바꿔준다.
labels은 [0,1, ... ,9]인 벡터형태이구, outputs에서 나오는 예측값은 10개 노드를 가진 벡터로 나오는데, 혹시 커스터마이징하다가 labels를 원핫인코딩하면 criteron을(outputs, labels) 에서 에러가 나게되니 주의하자.
loss_ = [] # loss 저장용 리스트
n = len(trainloader) # 배치개수
for epoch in range(10): # 10회 반복
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device) # 배치 데이터
optimizer.zero_grad() # 배치마다 optimizer 초기화
outputs = net(inputs) # 노드 10개짜리 예측값 산출
loss = criterion(outputs, labels) # 크로스 엔트로피 손실함수 계산 optimizer.zero_grad() # 배치마다 optimizer 초기화
loss.backward() # 손실함수 기준 역전파
optimizer.step() # 가중치 최적화
running_loss += loss.item()
loss.backward() # 손실함수 기준 역전파
optimizer.step() # 가중치 최적화
running_loss += loss.item()
loss_.append(running_loss / n)
print('[%d] loss: %.3f' %(epoch + 1, running_loss / len(trainloader)))
loss를 그래프로 그려보면 학습이 잘 진행된 것을 확인할 수 있다. 모델이 복잡하지 않고 단순하기 때문에 모델을 구성하는 것과 학습하는 과정에 의의를 두자.
plt.plot(loss_)
plt.title(loss)
plt.xlabel('epoch')
plt.show()

모델을 저장하는 것을 살펴보자. 경로를 지정해주고, torch.save 를 저장하면된다. net.state_dict은 parameter정보가 들어가게 된다.
PATH = './cifar_net.pth' # 모델 저장 경로
torch.save(net.state_dict(), PATH) # 모델 저장장저장한 모델을 다시 불러와보자. 모델 불러오기는 엄밀히 말하면 모델의 parameter를 불러오는 것이다. 모델의 뼈대를 먼저 선언하고나서 모델의 parameter를 불러와서 pretrained model를 만든다.
gpu용 모델을 만들었기 때문에 gpu용 모델로 뼈대를 만들고, parameter를 덮어씌워준다.
net = Net().to(device) # 모델 선언
net.load_state_dict(torch.load(PATH)) # 모델 parameter 불러오기
이제 모델의 정확도를 구해보자.
correct = 0
total = 0
with torch.no_grad(): # 파라미터 업데이트 같은거 안하기 때문에 no_grad를 사용.
# net.eval() # batch normalization이나 dropout을 사용하지 않았기 때문에 사용하지 않음. 항상 주의해야함.
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 10개의 class중 가장 값이 높은 것을 예측 label로 추출.
total += labels.size(0) # test 개수
correct += (predicted == labels).sum().item() # 예측값과 실제값이 맞으면 1 아니면 0으로 합산.
print(f'accuracy of 10000 test images: {100*correct/total}%')
outputs.data # 한 epoch에서 각 batch에서 나온 여기서는 8개의 배치라서 8개의 각 배치에 대한 10개의 class에 대한 score 산출.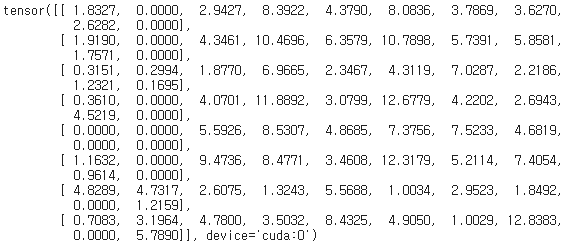
predicted # 어느 한 배치의 분류 예측값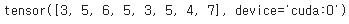
predicted를 통해 epoch한번에 8개의 배치에 대해 각각 3, 5, 6, 5, 3, 5, 4, 7 이라는 예측값을 얻을 수 있다.
ref)
www.analyticsvidhya.com/blog/2019/10/building-image-classification-models-cnn-pytorch/
Convolutional Neural Network Pytorch | CNN Using Pytorch
Learn how to build convolutional neural network (CNN) models using PyTorch. Work on an image classification problem by building CNN models.
www.analyticsvidhya.com
deeplearningbro
'딥러닝' 카테고리의 다른 글
| 컴퓨터 비전에서 딥러닝은 어떻게 활용될까? (0) | 2021.05.05 |
|---|---|
| pytorch로 구현하는 RNN(Recurrent Neural Network) (10) | 2021.04.14 |
| Pytorch로 구현하는 Multi-Layer Perceptron (0) | 2021.04.13 |
| pytorch 기초 문법(tensor, backpropagation, data load) (0) | 2021.04.12 |
| RNN (0) | 2021.04.10 |




댓글