구글에 연구원들이 쓴 구글의 유투브 추천시스템에 관한 논문이다. 오역과 다소 약한 설명이 있을 수 있으니 참고 바란다.
ABSTRACT
We discuss the video recommendation system in use at YouTube, the world’s most popular online video community. The system recommends personalized sets of videos to users based on their activity on the site. We discuss some of the unique challenges that the system faces and how we address them. In addition, we provide details on the experimentation and evaluation framework used to test and tune new algorithms. We also present some of the findings from these experiments.
-> 유투브에서 사용하는 영상 추천 시스템에 대해 다룬다. 이 시스템은 사이트에서 유저들의 행동을 기반으로 유저들을 위한 개인화된 영상(개개인에게 볼만한 영상)들을 추천한다. 시스템이 직면한 몇가지 독특한 부분을 다루며, 어떻게 그 것들을 설명하는지에 대해 다룬다.
새로운 알고리즘의 튜닝과 테스트를 위하여 실험, 평가 프레임워크에 대해 자세히 설명한다. 이러한 실험을 통한 발견에 대해서도 말하고자 한다.
1. INTRODUCTION
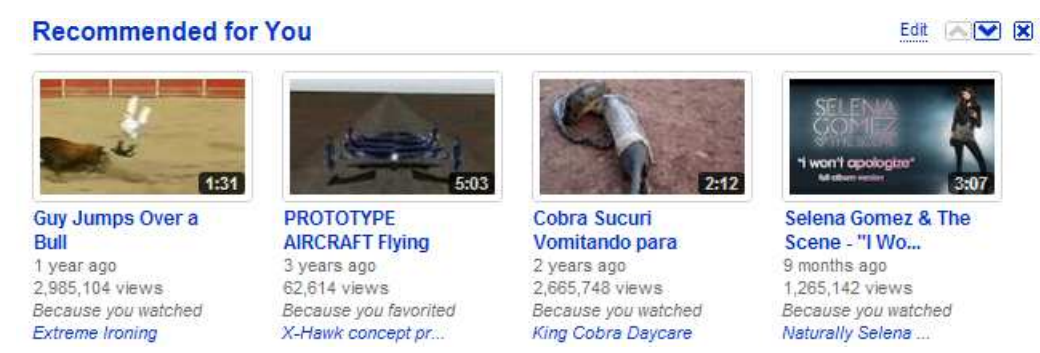
Personalized recommendations are a key method for information retrieval and content discovery in today’s informationrich environment. Combined with pure search (querying) and browsing (directed or non-directed), they allow users facing a huge amount of information to navigate that information in an efficient and satisfying way. As the largest and most-popular online video community with vast amounts of user-generated content, YouTube presents some unique opportunities and challenges for content discovery and recommendations. Founded in February 2005, YouTube has quickly grown to be the world’s most popular video site. Users come to YouTube to discover, watch and share originally-created videos. YouTube provides a forum for people to engage with video content across the globe and acts as a distribution platform for content creators. Every day, over a billion video plays are done across millions of videos by millions of users, and every minute, users upload more than 24 hours of video to YouTube. In this paper, we present our video recommendation system, which delivers personalized sets of videos to signed in users based on their previous activity on the YouTube site (while recommendations are also available in a limited form to signed out users, we focus on signed in users for the remainder of this paper). Recommendations are featured in two primary locations: The YouTube home page (http://www.youtube.com) and the “Browse” page at http: //www.youtube.com/videos. An example of how recommendations are presented on the homepage can be found in Figure 1.
-> 개인화 추천은 오늘날 정보화 시대에서 콘텐츠 발견이나 정보 검색에 있어서 중요한 도구다. 쿼리와 같은 검색과 브라우징을 합치게 되면, 이것은 거대한 정보의 양에 직면한 유저들에게 효율적이고 만족스러운 방법으로 정보를 탐색할 수 있게 도와준다. 유투브는 콘텐츠 발견과 추천을 위한 유니크한 기회들을 제공한다.
2005년 2월에 설립된 뒤 빠르게 가장 인기있는 영상 사이트로 성장했다. 유저들은 기존에 만들어졌던 영상물들을 공유하고 시청하거나 찾아보러 유투브로 접속한다. 유투브는 전세계적으로 영상 콘텐츠를 끌어들이고, 콘텐츠 크리에이터를 위한 플랫폼을 제공한다.
이 논문에서는 유투브 사이트에 그들의 이전 행동들을 토대로 가입된 유저들에게 맞춤형 영상물들을 제공하는 영상 추천 시스템에 대하여 설명한다. (제한적인 형태로 가입되어 있지 않은 유저에게도 추천이 가능하지만 가입 유저를 대상으로 한 추천에 초점을 맞춘다.)
추천은 홈페이지인 www.youtube.com과 www.youtube.com/videos로 그 특징이 나뉘는데 홈페이지에서의 추천과 같은 경우는 그림 1과 같은 것을 예로 들 수 있다.

1.1 Goals
Users come to YouTube for a wide variety of reasons which span a spectrum from more to less specific: To watch a single video that they found elsewhere (direct navigation), to find specific videos around a topic (search and goal-oriented browse), or to just be entertained by content that they find interesting. Personalized Video Recommendations are one way to address this last use case, which we dub unarticulated want. As such, the goal of the system is to provide personalized recommendations that help users find high quality videos relevant to their interests. In order to keep users entertained and engaged, it is imperative that these recommendations are updated regularly and reflect a user’s recent activity on the site. They are also meant to highlight the broad spectrum of content that is available on the site. In its present form, our recommendation system is a top-N recommender rather than a predictor [4]. We review how we evaluate the success of the recommendation system in section 3 of this paper. An additional primary goal for YouTube recommendations is to maintain user privacy and provide explicit control over personalized user data that our backend systems expose. We review how we address this goal in section 2.5.
-> 유저들은 다양한 이유로써 유투브에 접근한다. 직접적인 검색으로 원하는 하나의 영상을 찾는 것, 토픽과 관련된 특정 영상을 찾는 것, 그리고 흥미를 위해서 콘텐츠에 의해 즐기는 것이다. 맞춤형 영상 추천은 위 예시의 마지막 케이스에 대한 내용이다.
이 시스템의 목표는 맞춤형 추천으로 유저들에게 그들의 흥미와 연관된 고품질의 영상을 찾을 수 있게 도와 주는 것이다. 유저들을 끌어들이고 계속 즐기게끔 하기 위해서, 사이트에 유저들의 최신 행동을 반영하고 규칙적으로 업데이트 하는 것은 피할 수 없다.
현재 우리의 추천시스템은 예측기라기 보다는 top-N 추천기이다. (top-N은 N개의 상위 개체를 추천한다는 의미.) 이 논문의 섹션 3에서 추천시스템의 성능을 어떻게 평가하는지 알아볼 것이다. 추가적으로 유투브 추천 시스템의 중요한 목표는 유저들의 프라이버시를 유지하는 것이고 맞춤형 유저 데이터에 대한 분명한 통제를 하는 것이다.
1.2 Challenges
There are many aspects of the YouTube site that make recommending interesting and personally relevant videos to users a unique challenge: Videos as they are uploaded by users often have no or very poor metadata. The video corpus size is roughly on the same order of magnitude as the number of active users. Furthermore, videos on YouTube are mostly short form (under 10 minutes in length). User interactions are thus relatively short and noisy. Compare this to user interactions with movie rental or purchase sites such as Netflix or Amazon where renting a movie or purchasing an item are very clear declarations of intent. In addition, many of the interesting videos on YouTube have a short life cycle going from upload to viral in the order of days requiring constant freshness of recommendation.
-> 유투브 사이트에는 여러 특징들이 있다. 유저들에 의해 업로드된 영상들은 종종 메타데이터(사용자,시청자 정보나 혹은 평점과 같은 것을 의미하는 것 같음.)가 없거나 매우 부족하다. 영상의 코퍼스(영상들의 집합 단위를 얘기함.)는 활동적인 유저들의 수와 대략적으로 같은 크기이다. 게다가 유투브의 영상들은 내부분 크기가 짧다.(10 분 이내.) 그러므로 유저 간의 상호작용은 상대적으로 짧거나 잡음이 많다. 영화대여나 상품 구입과 유저 간의 상호작용을 비교해보면 특히 영화 대여, 상품 구매 사이트인 넷플릭스나 아마존과 같은 경우는 의도 자체가 분명하다고 할 수 있다. 게다가 유투브의 많은 흥미로운 영상들은 수명이 짧다.
2. SYSTEM DESIGN
The overall design of the recommendation system is guided by the goals and challenges outlined above: We want recommendations to be reasonably recent and fresh, as well as diverse and relevant to the user’s recent actions. In addition, it’s important that users understand why a video was recommended to them. The set of recommended videos videos is generated by using a user’s personal activity (watched, favorited, liked videos) as seeds and expanding the set of videos by traversing a co-visitation based graph of videos. The set of videos is then ranked using a variety of signals for relevance and diversity. From an engineering perspective, we want individual components of the system to be decoupled from each other, allowing them to be understood and debugged in isolation. Given that our system is part of the larger YouTube ecosystem, recommendations also needs to be resilient to failure and degrade gracefully in case of partial failures. As a consequence, we strive to minimize complexity in the overall system.
-> 전반적인 추천시스템의 디자인은 위와 같은 목표와 도전들에 의해 영향을 받는다. 추천시스템이 합리적으로 최신이며 또 신선했으면 좋겠고, 유저들의 현재 행동과 관련되어 있고 또 다양했으면 한다. 게다가 유저들이 왜 이 영상이 나한테 추천됐지? 를 이해하는 것 자체도 중요하다.
추천된 영상 셋트들은 시드(프로그램의 고정값)로써 유저의 개인적인 행동(watched, favorited, liked videos)을 사용해서 생성이 된다. 영상의 그래프를 기반으로 해서 공동 방문자(coocurrence)에 의한 영상들의 집합을 확장하는 중이다. 영상 셋은 관련성과 다양성에 대한 다양한 지표를 사용해서 랭킹을 결정한다.
엔지니어적 관점에서, 시스템의 개별요소를 서로 분리하고, 그들을 이해하고 고립된 상태에서 디버깅할 수 있기를 원한다. 우리의 시스템이 더 큰 유투브 생태계의 일부라는 것을 감안할 때, 추천들은 부분적인 실패의 경우 탄력적이게 저하될 필요가 있다. 결과적으로 전체 시스템의 복잡성을 최소화하기 위해 노력한다.
2.1 Input data
During the generation of personalized video recommendations we consider a number of data sources. In general, there are two broad classes of data to consider: 1) content data, such as the raw video streams and video metadata such as title, description, etc, and 2) user activity data, which can further be divided into explicit and implicit categories. Explicit activities include rating a video, favoriting/liking a video, or subscribing to an uploader. Implicit activities are datum generated as a result of users watching and interacting with videos, e.g., user started to watch a video and user watched a large portion of the video (long watch). In all cases, the data that we have at our disposal is quite noisy: Video metadata can be non-existent, incomplete, outdated, or simply incorrect; user data only captures a fraction of a user’s activity on the site and only indirectly measures a user’s engagement and happiness, e.g., the fact that a user watched a video in its entirety is not enough to conclude that she actually liked it. The length of the video and user engagement level all influence the signal quality. Moreover, implicit activity data is generated asynchronously and can be incomplete, e.g., the user closes the browser before we receive a long-watch notification.
-> 맞춤형 영상 추천을 생성하면서 많은 데이터 소스를 고려한다. 일반적으로 두가지 클래스를 고려한다. 1) 영상 스트림이나 제목이나 줄거리와 같은 영상 메타데이터와 같은 콘텐츠 데이터 그리고 2) 사용자 활동 데이터와 같이 명시적 및 암시적 범주로 나눌 수 있다. 명시적 활동에는 영상 평가, 좋아요, 구독하기를 포함한다. 사용자가 영상을 보고 상호작용한 결과로 암시적 활동들이 생성된다. 예를 들면 사용자는 영상을 보기 시작했고, 영상의 많은 부분을 시청했다(장시간) 같은 것이 있다.
모든 경우에 처리할 수 있는 데이터는 상당이 잡음이 심하다. 영상 메타데이터는 존재하지 않거나 구식이거나 단순히 부정확할 수 있다. 사용자 데이터는 사이트에서 사용자의 활동의 일부만을 포착하고 사용자의 참여와 즐거움을 간접적으로 측정할 뿐이다. 예를들어 사용자가 영상 전체를 보았다는 사실 자체가 그것을 좋아한다고 결론짓기는 충분하지 않다. 사용자 참여 레벨과 영상의 길이가 모두 신호 품질에 영향을 미친다. 게다가 암시적 활동 데이터는 비동기적으로 생성되고 불오나전할 수 있다. 예컨데 사용자는 장기 시청 알림을 받기 전에 브라우저를 닫는다.
2.2 Related Videos
One of the building blocks of the recommendation system is the construction of a mapping from a video vi to a set of similar or related videos Ri. In this context, we define similar videos as those that a user is likely to watch after having watched the given seed video v. In order to compute the mapping we make use of a well-known technique known as association rule mining [1] or co-visitation counts. Consider sessions of user watch activities on the site. For a given time period (usually 24 hours), we count for each pair of videos (vi, vj ) how often they were co-watched within sessions. Denoting this co-visitation count by cij , we define the relatedness score of video vj to base video vi as: r(vi, vj ) = cij f(vi, vj ) (1) where ci and cj are the total occurrence counts across all sessions for videos vi and vj , respectively. f(vi, vj ) is a normalization function that takes the “global popularity” of both the seed video and the candidate video into account. One of the simplest normalization functions is to simply divide by the product of the videos’ global popularity: f(vi, vj ) = ci · cj . Other normalization functions are possible. See [6] for an overview of possible choices. When using the simple product of cardinalities for normalization, ci is the same for all candidate related videos and can be ignored in our setting, so we are normalizing only by the candidate’s global popularity. This essentially favors less popular videos over popular ones. We then pick the set of related videos Ri for a given seed video vi as the top N candidate videos ranked by their scores r(vi, vj ). Note that in addition to only picking the top N videos, we also impose a minimum score threshold. Hence, there are many videos for which we will not be able to compute a reliable set of related videos this way because their overall view count (and thereby co-visitation counts with other videos) is too low. Note that this is a simplified description. In practice there are additional problems that need to be solved—presentation bias, noisy watch data, etc.—and additional data sources beyond co-visitation counts that can be used: sequence and time stamp of video watches, video metadata, etc. 294 The related videos can be seen as inducing a directed graph over the set of videos: For each pair of videos (vi, vj ), there is an edge eij from vi to vj iff vj ∈ Ri, with the weight of this edge given by (1).
-> 추천시스템의 구성 요소 중 하나는 영상$v_{i}$에서 유사하거나 관련된 영상들을 $R_{i}$로 매핑하는 것이다. 이러한 맥락에서 유사한 영상들이라는 것을 정의한다. 이는 한 사용자가 주어진 영상 $v$를 본 후에 시청할 가능성이 있는 것으로 정의한다. 매핑을 계산하기 위해서 규칙 기반 마이닝[1] 또는 동시 방문 수와 같이 잘 알려진 기법을 사용한다. 사이트에서 사용자의 시청 활동 세션을 고려하자. 주어진 시간 동안(대게 24시간), 우리는 얼마나 사용자들이 세션들에서 동시에 시청을 하였는지 각 영상들의 쌍 $(v_{i}, v_{j})$ 에 대한 카운트를 한다. 동시 방문을 $c_{ij}$를 명시하면서, 기본 영상 $v_{i}$와 영상 $v_{j}$ 사이의 관계 스코어를 아래와 같이 정의한다.
$r(v_{i}, v_{j}) = \frac{c_{ij}}{f((v_{i},v_{j}))}$ (1)
여기서 $c_{i}$와 $c_{j}$는 각각 영상 $v_{i}$와 $v_{j}$의 모든 세션에서의 총 발생 횟수이다. $f(v_{i}, v_{j})$는 시드 영상과 후보 영상의 "global popularity"(전체적인 인기)를 모두 고려한 정규화 함수다. 가장 간단한 정규화 기능 중 하나는 영상의 "global popularity": $f(v_{i}, v_{j}) = c_{i}\cdot c_{j}$ 로 $c_{ij}$를 나누는 것이다. 가능한 선택의 개요는 [6]을 참조. 정규화를 하기 위해 카디널리티(전체 행에 대한 특정 컬럼의 중복 수치.)의 간단한 곱을 사용 할 때, $c_{i}$는 모든 후보 연관 영상들과 동일하고, 우리의 설정 환경에선 무시될 수 있으므로 후보영상의 "global popularity"에 국한하여 정규화한다. 이것은 인기있는 영상보다 인기가 떨어지는 영상을 선호하게 된다.
그런 다음 주어진 시드 영상 $v_{i}$에 대한 관련 영상 셋 $R_{i}$을 스코어 $r(v_{i}, v_{j})$에 의해 랭킹이 매겨진 후보 영상을 상위 N개에 의해서 선정한다.
또한 상위 N개의 영상들만 선택하는 것 외에도 최소 점수 임계 값을 부여한다. 그러나 계산할 수 없는 연관 영상 셋들이 많이 존재한다. 그 이유는 그러한 영상들의 시청률(그리고 그에 따라 다른 영상과의 동시 시청률)이 매우 낮기 때문이다.
이것은 단순화된 설명이고, 실제로는 추가적인 문제들이 있다. 시청의 편향, 잡음이 심한 영상 데이터 등과 함께 볼 수 있는 공동 방문자 수를 넘어선 추가적인 데이터 소스들이 있다. 예컨데 영상 메타데이터, 시청 시간의 타임 스탬프와 시퀀스 등이다.
연관 영상은 영상 셋에 대한 방향성이 있는 그래프(directed graph)를 유도하는 것으로 볼 수 있다. 각 영상 쌍 $(v_{i}, v_{j})$에 대해 하나의 엣지 $e_{ij}$는 $v_{i}$에서 $v_{j}$ iff(if and only if: 양쪽다참or거짓) $v_{j} \in R_{i}$ 이고, 이 엣지의 가중치는 (1)에 의해 주어진다.
2.3 Generating
Recommendation Candidates To compute personalized recommendations we combine the related videos association rules with a user’s personal activity on the site: This can include both videos that were watched (potentially beyond a certain threshold), as well as videos that were explicitly favorited, “liked”, rated, or added to playlists. We call the union of these videos the seed set. In order to obtain candidate recommendations for a given seed set S, we expand it along the edges of the related videos graph: For each video vi in the seed set consider its related videos Ri. We denote the union of these related video sets as C1: C1(S) = [ vi∈S Ri (2) In many cases, computing C1 is sufficient for generating a set of candidate recommendations that is large and diverse enough to yield interesting recommendations. However, in practice the related videos for any videos tend to be quite narrow, often highlighting other videos that are very similar to the seed video. This can lead to equally narrow recommendations, which do achieve the goal of recommending content close to the user’s interest, but fail to recommend videos which are truly new to the user. In order to broaden the span of recommendations, we expand the candidate set by taking a limited transitive closure over the related videos graph. Let Cn be defined as the set of videos reachable within a distance of n from any video in the seed set: Cn(S) = [ vi∈Cn−1 Ri (3) where C0 = S is the base case for the recursive definition (note that this yields an identical definition for C1 as equation (2)). The final candidate set Cfinal of recommendations is then defined as: Cfinal = ([N i=0 Ci) \ S (4) Due to the high branching factor of the related videos graph we found that expanding over a small distance yielded a broad and diverse set of recommendations even for users with a small seed set. Note that each video in the candidate set is associated with one or more videos in the seed set. We keep track of these seed to candidate associations for ranking purposes and to provide explanations of the recommendations to the user.
-> 개인화된 추천을 계산하기 위해 관련 영상 연관 규칙을 사이트에서 사용자의 개인 활동과 결합한다: 여기에는 두 영상 다 시청이 된(잠재적으로 특정 임계치를 넘어선) 영상들이 있고 또한 명시적으로 즐겨찾기, 좋아요, 등급, 플레이리스트 추가 가 있다. 이것들을 시드 집합(seed set)이라 부른다.
주어진 시드 집합 $S$에 대한 후보 추천을 얻기 위해 관련 영상 그래프의 엣지들을 따라 확장시킨다. 시드 집합에 각 영상 $v_{i}$에 대해 관련 영상들 $R_{i}$를 고려하자. 이 관련 영상 셋의 조합을 $C_{1}$으로 아래와 같이 나타낸다. $v_{i}$가 포함된 집합 $S$에 대해 각각 $v_{i}$에 대한 후보 영상 셋 $R_{i}$ 들을 전부 모아 놓은 집합을 $C_{1}$과 같이 나타낸다.
$C_{1}(S) = \bigcup_{v_{i} \in S}R_{i}$ (2)
많은 경우, $C_{1}$을 계산하는 것은 흥미로운 추천을 생성하는데에 충분하고 다양하며 다양하고 큰 후보 추천들을 생성하기에 충분하다. 그러나 어떤 영상에 대한 관련 영상을 훈련시키는 것은 매우 좁은 경향이 있으며 종종 시드 영상과 매우 유사한 다른 영상을 강조하곤 합니다. 이는 사용자의 관심에 가까운 콘텐츠를 추천하는 목표는 달성하지만 사용자에게 진정으로 새로운 영상을 추천하지 못하는 등 똑같이 좁은 추천으로 이어질 수 있다.
추천의 범위를 넓히기 위해서, 관련 영상 그래프를 통해 제한된 전이 폐쇄(transitive closure)를 취함으로써 후보 집합을 확장한다. $C_{n}$을 시드 집합의 모든 영상으로부터 $n$ 거리 내에 도달가능한 영상 셋으로 정의한다.
$C_{n}(S) = \bigcup_{v_{i} \in C_{n-1}}R_{i}$ (3)
여기서 $C_{0} = S$는 재귀적 정의의 기본 케이스이다.(이는 방정식 (2)로 $c_{1}$에 대해 동일한 정의를 산출하는 것을 말한다. ) 최종 후보 $C_{final}$는 다음과 같이 설정한다.
$C_{final} = (\bigcup_{i=0}^{N}C_{i}) / S$ (4)
관련 영상 그래프의 높은 분기 요소(각 노드의 하위 요소 수)로 인해 작은 거리에 걸쳐 확장하면 작은 시드 집합을 가진 사용자에게도 광범위하고 다양한 추천 셋이 산출된다는 것을 발견했다. 후보 집합의 각 영상은 시드 집합의 하나 이상의 영상과 관련이 되게 된다. 순위를 매기는 목적으로 연관 후보들에 이 시드를 추적하고 사용자에게 추천에 대한 설명을 제공한다.
2.4 Ranking
After the generation step has produced a set of candidate videos they are scored and ranked using a variety of signals. The signals can be broadly categorized into three groups corresponding to three different stages of ranking: 1) video quality, 2) user specificity and 3) diversification. Video quality signals are those signals that we use to judge the likelihood that the video will be appreciated irrespective of the user. These signals include view count (the total number of times a video has been watched), the ratings of the video, commenting, favoriting and sharing activity around the video, and upload time. User specificity signals are used to boost videos that are closely matched with a user’s unique taste and preferences. To this end, we consider properties of the seed video in the user’s watch history, such as view count and time of watch. Using a linear combination of these signals we generate a ranked list of the candidate videos. Because we display only a small number of recommendations (between 4 and 60), we have to choose a subset of the list. Instead of choosing just the most relevant videos we optimize for a balance between relevancy and diversity across categories. Since a user generally has interest in multiple different topics at differing times, videos that are too similar to each other are removed at this stage to further increase diversity. One simple way to achieve this goal is to impose constraints on the number of recommendations that are associated with a single seed video, or by limiting the number of recommendations from the same channel (uploader). More sophisticated techniques based on topic clustering and content analysis can also be used.
-> 생성 단계에서 일련의 후보 영상을 생성한 후 다양한 신호를 사용하여 점수를 매기고, 순위를 매길 수 있다. 신호는 3 단계의 순위에 해당하는 3가지 그룹으로 광범위하게 분류할 수 있다. 1) 영상 품질, 2) 사용자 특이성 및 3) 다양화.
영상 품질 신호는 사용자와 상관없이 영상이 평가될 가능성을 판단하기 위해 사용하는 신호다. 이러한 신호로는 영상 시청 횟수, 등급, 댓글, 영상 주변 활동 선호 및 공유, 업로드 시간이 있다.
사용자 특이성 신호는 사용자의 고유한 취향과 선호도와 밀접하게 일치하는 영상을 활성화하는데 사용한다. 이를 위해 시청 횟수 및 타임 스탬프와 같은 사용자의 시간 기록에서 시드 영상의 특성을 고려한다.
이러한 신호들의 선형 조합을 이용하여 후보 영상들의 랭크된 리스트를 생성한다. 소수의 추천사항(4~60개)만 표시하기 때문에 목록의 하위 집합을 선택해야 한다. 범주에 따라 관련성과 다양성 사이의 균형을 위해 가장 적절한 영상을 선택하는 대신 최적화를 한다. 사용자는 일반적으로 서로 다른 시간에 여러가지 주제에 관심을 가지기 때문에 이 단계에서 서로 너무 유사한 영상을 제거하여 다양성을 더욱 증가시킨다. 이 목표를 달성하는 한 가지 간단한 방법은 단일 시드 영상과 관련된 추천 횟수에 제약을 가하거나, 동일한 채널(업로더)에서 추천 횟수를 제한하는 것이다. 토픽 클러스터링 및 콘텐츠 분석을 기반으로 한 보다 정교한 기법도 사용할 수 있다.
2.5 User Interface
Presentation of recommendations is an important part of the overall user experience. Figure 1 shows how recommendations are currently presented on YouTube’s home page. There are a few features worth noting: First, all recommended videos are displayed with a thumbnail and their (possibly truncated) title, as well as information about video age and popularity. This is similar to other sections on the homepage and helps users decide quickly whether they are interested in a video. Furthermore, we add an explanation with a link to the seed video which triggered the recommendation. Last, we give users control over where and how many recommendations they want to see on the homepage. As mentioned in section 2.4, we compute a ranked list of recommendations but only display a subset at serving time. This enables us to provide new and previously unseen recommendations every time the user comes back to the site, even if the underlying recommendations have not been recomputed.
-> 추천 영상을 제시하는 것은 전체 사용자 경험의 중요한 부분이다. 그림 1은 유투브 홈페이지에서 추천 영상이 어떻게 제시되는지 보여준다. 여기엔 주목할만한 몇가지 특징이 있다.
첫째, 추천 영상은 모두 썸네일과 그 제목과 영상과 인기에 대한 정보로 표시된다. 이것은 홈페이지의 다른 섹션과 유사하며 사용자가 영상에 관심이 있는지 여부를 신속하게 결정할 수 있도록 도와준다. 또한, 추천을 촉발시킨 시드 영상에 대한 설명을 추가한다. 마지막으로, 사용자들에게 홈페이지에서 그들이 보고 싶은 장소와 추천 사항들을 통제할 수 있게 해준다.
2.4절에서 언급했듯이, 추천 목록의 순위를 계산하지만 제공 시간에는 부분 집합만 표시한다. 이를 통해 사용자가 사이트로 돌아올 때마다 기본 추천 사항이 재계산되지 않았더라도 새롭고 이전에 보이지 않았던 추천을 제공할 수 있다.
2.6 System Implementation
We choose a batch-oriented pre-computation approach rather than on-demand calculation of recommendations. This has the advantages of allowing the recommendation generation stage access to large amounts of data with ample amounts of CPU resources while at the same time allowing the serving of the pre-generated recommendations to be extremely low latency. The most significant downside of this approach is the delay between generating and serving a particular recommendation data set. We mitigate this by pipelining the recommendation generation, updating the data sets several times per day. The actual implementation of YouTube’s recommendation system can be divided into three main parts: 1) data collection, 2) recommendation generation and 3) recommendation serving.The raw data signals previously mentioned in section 2.1 are initially deposited into YouTube’s logs. These logs are processed, signals extracted, and then stored on a per user basis in a Bigtable [2]. We currently handle millions of users and tens of billions of activity events with a total footprint of several terabytes of data. Recommendations are generated through a series of MapReduces computations [3] that walk through the user/video graph to accumulate and score recommendations as described in section 2. The generated data set sizes are relatively small (on the order of Gigabytes) and can be easily served by simplified read-only Bigtable servers to YouTube’s webservers; the time to complete a recommendation request is mostly dominated by network transit time.
-> 추천의 온디멘드(on-demand) 계산보다는 배치 지향적인 사전 계산 접근법을 선택한다. 이것은 추천 생성 단계가 충분한 양의 CPU 리소스를 가진 다량의 데이터에 액세스 하는 동시에 사전 생성된 추천의 서비스가 극도로 낮은 잠재성을 허용하는 이점을 가지고 있다. 이 접근법의 가장 중요한 단점은 특정 권장 데이터 셋을 생성하고 제공하는데 지연이 된다는 것이다. 그 추천 생성을 파이프라인화하고, 하루에 여러번 데이터 셋을 업데이트 함으로써 완화시킨다.
유튜브 추천시스템의 실제 구현은 1) 데이터 수집, 2) 추천 생성, 3) 추천 서비스 의 세가지 주요 부분으로 나눌 수 있다.
2.1절에서 앞서 언급한 원시 데이터 신호는 처음에 유튜브의 로그에 저장된다. 이러한 로그는 처리되고, 신호 추출되고, 사용자별로 큰 테이블[2]에 저장된다. 현재 수백만 명의 사용자와 수천만 개의 활동 이벤트를 처리하고 있으며, 총 몇 테라바이트의 데이터를 가지고 있다.
추천은 섹션 2에서 설명한대로 추천 사항을 축적하고 점수를 매기기 위해 사용자/영상 그래프를 통한 일련의 맵리듀스 계산을 통해 생성된다.
생성된 데이터 셋 크기는 상대적으로 작으며(기가 바이트 순서로) 단순화된 읽기 전용 빅 테이블 서버에서 유투브의 웹 서버로 쉽게 제공할 수 있다. 추천 요청을 완료하는 시간은 주로 네트워크 전송 시간에 의해 지배됩니다.
3. EVALUATION
In our production system we use live evaluation via A/B testing [5] as the main method for evaluating the performance of the recommendation system. In this method, live traffic is diverted into distinct groups where one group acts as the control or baseline and the other group is exposed to a new feature, data, or UI. The two groups are then compared against one another over a set of predefined metrics and possibly swapped for another period of time to eliminate other factors. The advantage of this approach is that evaluation takes place in the context of the actual website UI. It’s also possible to run multiple experiments in parallel and get quick feedback on all of them. The downsides are that not all experiments have reasonable controls that can be used for comparison, the groups of users must have sufficient traffic to achieve statistically significant results in a timely manner and evaluation of subjective goals is limited to the interpretation of a relatively small set of pre-defined metrics. To evaluate recommendation quality we use a combination of different metrics. The primary metrics we consider include click through rate (CTR), long CTR (only counting clicks that led to watches of a substantial fraction of the video), session length, time until first long watch, and recommendation coverage (the fraction of logged in users with recommendations). We use these metrics to both track performance of the system at an ongoing basis as well as for evaluating system changes on live traffic.
-> 추천 시스템의 성능을 평가하기 위한 방법으로 A/B 테스트 [5]를 통한 실시간 평가를 사용한다. 이 방법에서, 실시간 트래픽은 하나의 그룹이 제어 또는 기준선 역할을 하고 다른 그룹이 새로운 특징, 데이터 또는 UI에 노출되는 별개의 그룹으로 전환된다. 그런 다음 두 그룹은 미리 정의된 행렬 셋에 대해 서로 비교되고 다른 요인을 제거하기 위해 다른 기간 동안 교환될 수 있다. 이 접근법의 장점은 평가가 실제 웹 사이트 UI의 맥락에서 이루어진다는 것이다. 또한 여러 실험을 병행해서 진행하여 모든 실험에 대한 빠른 피드백을 얻을 수도 있다. 단점은 모든 실험이 비교에 사용할 수 있는 합리적인 통제를 갖고 있는 것이 아니며, 사용자 그룹은 적절한 방식으로 통계적으로 유의미한 결과를 얻기 위해 충분한 트래픽을 가져야하며 주관적 목표에 대한 평가는 상대적으로 작은 사전 정의된 행렬 집합의 해석으로 제한된다.
추천 품질을 평가하기 위해 여러 행렬들의 조합을 사용한다. 중요하게 고려하는 지표는 클릭 비율(CTR), 긴 CTR(영상의 상당 부분을 시청으로 이끄는 카운트 클릭만 포함), 세션 길이, 첫 번째 긴 시청시간까지의 시간. 추천 범위(추천된 사용자 로그인 부분)를 포함한다. 이러한 행렬들을 이용하여 시스템의 성능을 추적하고 실시간 트래픽에서의 시스템 변경을 평가한다.
4. RESULTS
The recommendations feature has been part of the YouTube homepage for more than a year and has been very successful in context of our stated goals. For example, recommendations account for about 60% of all video clicks from the home page. Comparing the performance of recommendations with other modules on the homepage suffers from presentation bias (recommendations are placed at the top by default). To adjust for this, we look at CTR metrics from the “browse” pages and compare recommendations to other algorithmically generated video sets: a) Most Viewed - Videos that have received the most number of views in a day, b) Top Favorited - Videos that the viewers have added to their collection of favorites and c) Top Rated - Videos receiving most like ratings in a day. We measured CTR for these sections over a period of 21 days. Overall we find that co-visitation based recommendation performs at 207% of the baseline Most Viewed page when averaged over the entire period, while Top Favorited and Top Rated perform at similar levels or below the Most Viewed baseline. See figure 2 for an illustration of how the relative CTR varies over the period of 3 weeks.
-> 추천 기능은 1년 이상 유투브 홈페이지의 일부였으며 명시된 목표의 맥락에서 매우 성공적이었다. 예를 들어 추천은 홈페이지에서 모든 영상 클릭의 약 60%를 차지한다. 추천의 성능을 홈페이지의 다른 모듈과 비교하면 추천 영상제시의 편향(추천은 기본적으로 최상위에 위치한다.)이 발생한다. 이를 위해 'browse'페이지에서 CTR 행렬을 보고 다른 알고리즘으로 생성된 영상 셋과 추천을 비교한다. a) 하루 중 가장 많은 수의 조회수를 받은 가장 많은 시청률-영상, b) 시청자가 즐겨 찾기 모음에 추가한 Top Favorited-영상 및 c) 하루 중 가장 유사한 등급을 받은 최고 등급-영상.
21일 동안 이 구간의 CTR을 측정하였다. 전체적으로 전체 기간 동안 평균을 기준으로 가장 많이 보는 기준 페이지의 207%에서 공동 방문 기반 추천이 수행되는 반면, 가장 좋아하는 기준과 최고 등급은 비슷한 수준 또는 가장 많이 보는 기준선 이하에서 수행된다. 3주 동안 CTR이 어떻게 변하는지 그림 2를 참조하자.

5. ACKNOWLEDGMENTS
We would like to thank John Harding, Louis Perrochon and Hunter Walk for support and comments.
6. ADDITIONAL AUTHORS
Additional authors: Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, Dasarathi Sampath (all Google Inc, emails {ullas, sujoy, yuhe, lambert, blivingston, dasarathi}@google.com).
7. REFERENCES
[1] R. Agrawal, T. Imieli´nski, and A. Swami. Mining association rules between sets of items in large databases. SIGMOD Rec., 22(2):207–216, 1993. [2] F. Chang, J. Dean, S. Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, and R. E. Gruber. Bigtable: A distributed storage system for structured data. In USENIX ’07, pages 205–218, 2006. [3] J. Dean and S. Ghemawat. Mapreduce: Simplified data processing on large clusters. In OSDI ’04, pages 137–150, 2004. [4] M. Deshpande and G. Karypis. Item-based top-n recommendation algorithms. ACM Trans. Inf. Syst., 22(1):143–177, 2004. [5] S. Huffman. Search evaluation at Google. http://googleblog.blogspot.com/2008/09/ search-evaluation-at-google.html, 2008. [6] E. Spertus, M. Sahami, and O. Buyukkokten. Evaluating similarity measures: a large-scale study in the orkut social network. In KDD ’05, pages 678–684, New York, NY, USA, 2005. ACM.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. RecSys2010, September 26–30, 2010, Barcelona, Spain. Copyright 2010 ACM 978-1-60558-906-0/10/09 ...$10.00. -> 상업적 용도, 재배포를 위해선 돈을 내야한다. 저작권 관련 내용.
논문: https://dl.acm.org/doi/pdf/10.1145/1864708.1864770?download=true
'Reading' 카테고리의 다른 글
| A new approach for combining content-based and collaborative filters (0) | 2020.02.03 |
|---|---|
| Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions(2005) (0) | 2020.01.21 |
| Using Content-Based Filtering for Recommendation (0) | 2020.01.21 |
| Recommender systems survey(1) (0) | 2020.01.12 |
| 마음가면 (0) | 2020.01.04 |




댓글