Abstract
하이브리드 시스템을 제안하며, MovieLens 데이터를 사용했다.
1. Introduction
영화, 시놉시스, 참여자(배우, 감독, 대본작가)와 다른 사용자들의 의견을 잘 고려한 하이브리드 시스템을 개발했다.
2. Related Work
“A hybrid approach to making recommendations and its application to the movie domain” 는 요청시 등급 예측을 제공하는 하이브리드 시스템이다.
3.Content_Based and Collaborative Filtering
Demographic filtering은 유사한 인구통계학적 특징을 가진 사용자에게 동일한 요소를 추천한다. 이 접근 방식은 너무 일반적이고 시간이 지나 변화하는 관심사에 적응할 수 없다. 하지만 다른 필터링 접근과 결합할 때 유용한 기술이다.
Contents based filtering은 이전에 평가된 항목에 대한 설명을 기반으로 사용자에게 요소를 추천한다. 사용자가 과거에 좋아했던 항목과 비슷하다는 점을 활용한다. 사용자 프로필은 과거에 평가된 제품 또는 서비스에서 특징을 추출하여 작성된다. 이 시스템은 객관적 정보에만 기초하고 있다. 계속해서 유사한 항목의 아이템만을 추천하는 단점이 있다.
Collaborative filtering은 유사한 관심사를 가진 사람들의 정보를 가지고 추천을 제공한다. 명시적 혹은 암묵적 행동에 대한 패턴의 상관관계를 유사도를 통해서 구하여 추천 알고리즘에 적용한다. 새로운 항목이 추가될 경우나 평가가 없는 항목에 대한 경우에 cold-start문제가 발생한다. 만족할만한 점수를 주지 않는 사용자들 때문에 추천의 질이 떨어지거나, 사용자 수가 애초에 적으면 품질이 떨어지게 된다. 계산 또한 전체 이웃에 대한 것이라 피드백이 빠르지 않다.
Hybrid systems은 콘텐츠 기반 및 협업 필터링 특성을 활용한다. 이 둘의 상호보완적인 관계가 입증되기 때문이다.
4.Hybrid Filtering Approach
4.1 Data representation
본 논문의 구현은 MovieLens 데이터셋을 사용하였다. 인구통계학적 정보(성별, 직업, 연령 등)이 있지만 시스템 복잡성 증가를 정당화할 만큼 크지 않아 사용하지 않는다.
본 논문에서는 두 가지 요소를 고려하는데 먼저 개인들이 이미 본 영화와 비슷한 선호도를 가진 사람들이 좋아했던 영화, 감독, 대본 작가, 배우들을 고려한다. 마지막으로 영화의 요약도 검토한다.(제목 포함). 중요하지 않은 대명사나 접속사 같은단어는 제거되고, 필름을 특징짓기 위한 단어의 빈도를 계산한다.
콘텐츠만을 사용함으로써, 우리는 유사한 영화만을 제안하여 사용자를 지루하게 할 수 있다. 이러한 단점을 고려하기 위해서 다른 사용자의 의견이 고려되는데 물론, 유사하거나 특히 반대되는 선호도를 나타내는 것을 사용한다. 이렇게 콘텐츠 기반, 협업 필터링 기반을 기반으로 한 하이브리드 시스템으로 이어지게 된다.
실험에서 차원의 감소를 달성하기 위해 둘 이상의 영화에 참여하는 기여자들만 고려한다는 점에 유의해야한다.
따라서 데이터 셋은 각 영화의 특징을 가진 세 가지 주요 행렬로 구성된다.
(19개 장르 X 1682개 영화), 2. (4416명 배우 X 1682개 영화), 3. (8595 terms X 1682개 영화) 장르의 경우는 해당 장르에 해당되면 1, 아니면0. 배우 X 영화 행렬에서는 해당 배우가 출연하면 1, 아니면0. terms X 영화 행렬에서는 해당 영화 시놉시스에 포함된 단어가 있으면 1, 아니면0. 으로 구성된다.
4.2 Neural network-based content filtering
본 논문에서는 이러한 세가지 영화 특징에 해당하는 세 개의 신경망(MultiLayer Perceptrons)을 사용자별로 구성하여 시스템의 콘텐츠 필터링 부분을 설계하였다.
신경망의 주요 매개변수인 전이함수와 훈련스킴(Resilient Back Propagation)은 신경망 툴박스를 사용한 실험을 통해 결정되었다.
4.3 Collaborative part
활성 사용자와 다른 사용자 간의 상관관계를 찾는다. 상관계수 $r$을 가지고 평점과 조율을 한다. 평점을 높게 준 사람과 상관계수가 -0.6 이라면 활성사용자의 해당 항목에 대한 추천점수는 낮아지게 되는 것처럼 말이다.
4.4 Combination of filtering parts
1. 4가지 개별 기준에 의해 제안된 영화들을 선정한다. 기준은 장르, 배우, 요약, 다른 사용자의 의견(평점)을 말한다.
2. 높은 임계값을 사용하여 협업 기준을 만족하는 영화를 추가한다.
3. 콘텐츠 기준에 의해 제안된 영화를 추가한다. (특히 평가가 없는 신작 영화)
4. 정확히 두가지 콘텐츠 기준과 협업 기준에 의해 제안된 영화를 추가한다.
5. 정확히 두가지 콘텐츠 기준에 의해 제안된 영화를 추가한다.
6. 한가지 내용 기준에 의해 제안된 영화를 추가한다.
7. 마지막으로 영화들이 여전히 그 추천 모음에 빠져있다면, 가장 인기 있는 영화를 제안한다.
이런 식으로 항상 추천 모음을 갖출 수 있다고 보장할 수 있고, 제안된 영화가 완전한 추천 모음을 만들기에 부족하면 위의 7단계 절차를 따를 수 있다.
5. Experimental Results and Discussion
하나의 특징을 가지고 진행한 콘텐츠 기반 추천은 대충 60% 정도의 정밀도를 보인다. 즉 하나의 특징은 충분하지 않다는 소리다. 왜냐하면 다른 영화들에게도 공통적으로 적용되어 개별적 특징을 대표하기 힘들기 때문이다.
예를 들면 용이랑 성같은 게 나오는 영화는 그 장르가 사랑, SF, 테러가 될 수도 있다. 스티븐 스필버그에 나오는 외계인은 또 다른 영화에 나오는 외계인들이랑은 보통 비교할수 없다.
좋아할만한 영화를 모두 추천하는 것은 의미가 없다고 판단하여 성공확률을 높일 몇 편의 영화를 제안한다고 했다.(5편).
기술한 규칙 순서를 적용하면 다음과 같은 결과를 얻을 수 있다.

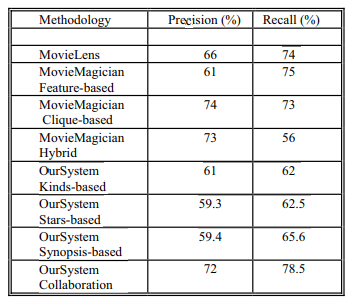
가장 밑에 Percentage of users with zero successes가 2.23% 라는 것은 추천할 수 없는 사용자가 2.23% 뿐이라는 것이다. 반면 사용자당 평균 성공률은 80%로 5편당 4편이 성공적으로 추천된다는 것을 의미한다. 이 비율은 다른 추천시스템의 정밀도와 비교하면 높은 수치이다. 개별적인 기준의 기여도를 증가시켜 퍼포먼스를 강화할 수 있다. 아래의 그림은 세가지 콘텐츠 기준 각각에 따라 총 영화 수의 함수로 정밀도를 묘사한다.
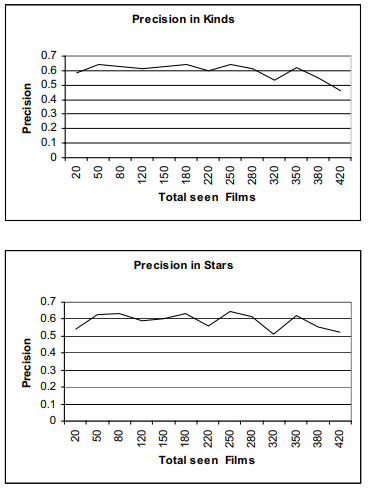
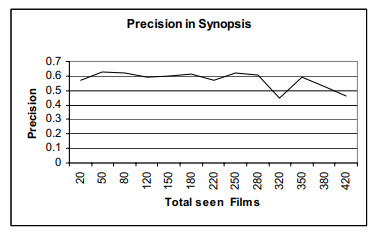
사용자가 많은 영화를 평가하면서 정밀도가 떨어지는 것은 다소 이상해 보이지만, 쉽게 설명이 가능하다. 사용자가 계속해서 영화를 평가함에 따라서 사용자는 영화의를 광범위하게 다루었을 가능성이 있다. 영화를 평가함에 따라 영화들은 이후에 완전히 다르게 평가되거나 완전히 달라지는 특징이 생기게 되는 와중에 말이다.
추후 흥미로운 연구로는 성능을 향상시킬 좋은 방법인지를 구별하기 위한 방법을 찾는 것이다.
또 다른 연구 분야는 이 셋이 너무 작을 때 사용자가 본 영화 셋을 dense하게 해주는 것이다. 위 그래프처럼 총 영화수가 작을 때 성능은 평균 보다 낮다.
아이디어를 연구하고 있다. 초기에는 특정 피쳐들 (장르, 배우, 시놉시스)를 기반으로 간단한 Kmeans 알고리즘을 사용하여 영화를 클러스터링 한다. 각 클러스터에 속하는 평가된 영화의 평균 등급이 계산되고, 이 값이 전체 클러스터에 할당된다. 그런 다음 사용자가 본 것과 비교하여 충분히 큰 클러스터의 가장 큰 특징적인 영화를 발견하여 학습 셋에 추가한다.



댓글