이번 장에서는 NLP 분야에서 워드 임베딩의 방법론으로 사용되고 있는 Word2Vec의 Skip gram에 Negative Sampling을 더한 알고리즘을 추천시스템에 적용한 논문에 대해 리뷰를 한다.
아마존, 넷플릭스, 구글 플레이, 아이튠즈 스토어 같은 회사에서 위의 방식처럼 추천을 적용하여 서비스하고 있다. 이러한 single item recommendation(단일 아이템 추천)과 같은 경우에는 explicit 데이터인 평점 데이터로 이뤄진 traditional한 추천과는 다르다. single item recommendation같은 경우엔 명시적 사용자의 아이템에 대한 구매 의도와 아이템에 대한 흥미로 나타나기 때문에 아이템 유사도 기반의 이러한 추천은 user-to-item recommendation보다 CTR(Click-Through Rates) 같은게 더 높게 나타난다. 이는 곧 회사 매출이나 이익에 막대한 비중을 차지할 수 밖에 없다.
즉, 아이템 간의 유사도를 토대로 이뤄진 추천이 단순하지만서도 꽤 합리적이라는 것이다.
이 논문에서는 SGNS(Skip Gram Negative Sampling)을 item-based CF에 적용한다. "Item2Vec" 그리고 SVD와 비교를 해본다. 뭐 논문에서는 state-of-art 와 같이 새로운 혁신적인 기술을 소개한다는 느낌보다 이러한 시도를 통해 성공적인 결과물을 냈다는 것에 의의를 둔다.
SGNS 란
Skip gram 이라하면 단어 임베딩에서 몇 년전 등장한 Mikolov et al.(2013a) 가 저술한 아주 핫한 알고리즘이었다. 간략하게 설명하면 단어를 임베딩함에 있어서 특정 단어가 인풋으로 들어가게 되면 window size(고려할 주변 단어 크기) <-hyperparameter. 를 토대로 주변 단어와의 관계를 학습시킴으로써 기존의 원핫인코딩으로 단어는 부여된 수치외에 의미가 없었지만 skip gram을 통해 단어 벡터에 의미를 부여할 수 있게 된 알고리즘이다.
즉, 특정 단어와 다른 단어 사이의 관계를 설명할 수 있게 된 것이다. 타겟 단어를 가지고 context 단어가 무엇일지 예측하는 과정에서 학습하는 것이다. 그러므로 특정 타깃 단어의 주변의 context, 즉 분포정보를 임베딩에 함축한다.
skip gram의 알고리즘에 대해 알아보자.
우선 sequence 단어 $(w_{i})^{K}_{i=1}$ 과 사전 $W = \left \{w_{i} \right \}^{W}_{i=1}$ 가 있다. $w_{i}$는 한 시퀀스의 $K$개의 단어 중 $i$번째 단어에 해당되고, $W$는 사전에 총 단어 개수를 의미한다. skip gram의 목적은 아래의 term을 최대화 하는 것이다.
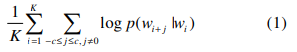
식 (1)이 의미하는 바는 타깃 단어 $w_{i}$ 주변에 window $c$ 만큼에 해당하는 단어들이 같이 등장할 확률에 대한 평균이고, 한 시퀀스에서 그 평균을 최대화하는 것이다.
이 말인 즉슨, 입력으로 들어간 타깃단어에 대해서 우리가 원하는 output인 그 주변 단어들이 등장할 확률을 최대화 시켜서 이들 간의 관계에 가중치를 주게 되서 결과적으로 타깃이 들어가면 주변 단어가 잘 등장하게 만든다고 생각하면 된다. 여기서 가중치를 주면서 의미부여하는게 조건부확률을 최대화시키는 과정이다.
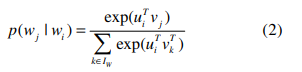
식 (2)는 softmax로써 activate function인데 hedden layer를 거치고 output을 낼 때 확률 값으로 변환해주기 위해 사용되는 것이다. 입력을 벡터로 주고 사영을 하고, 결과값이 벡터값으로 나오면 안되니 각 output단어들에 대해 확률로 표현하여 관계를 설명해주는 것이다.
$u_{i} \in U(\subset \mathbb{R}^{m})$ 과 $v_{i} \in V(\subset \mathbb{R}^{m})$은 각각 latent vector로 하이퍼파라미터로 지정한 $m$차원으로 벡터를 나타내는 것이다. 히든레이어 안에서의 계산에 대한 설명이다.
Negative Sampling이란
네거티브 샘플링은 간단하게 말하면 타깃 단어와 context 단어쌍이 주어졌을 때 해당 쌍이 positive sample(+)인지 negative sample(-)인지 이진 분류를 하는 과정에서의 학습이다. 쉽게 설명하면 타깃단어가 들어가면 결국 단어장에 존재하는 모든 단어들과의 비교를 통해서 확률을 구하는데 계산량이 너무 많아지기 때문에 이 계산량을 줄이기 위함이 목적이다.
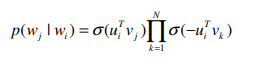
$N$은 네거티브 샘플의 개수(hyper parameter)를 말한다. $N$이 2라면 타깃단어를 입력으로 주고, window 하에 맺어진 쌍들로 구성되는 positive sample 1 개와 2($N$)개의 negative sample만을 고려하면 된다. 위의 식은 $N$만큼만 고려하겠다는 것이다. 네거티브 샘플링을 하지 않으면 저 $N$은 곧 $W$로 단어장 내의 전체 단어 개수가 된다.
네거티브 샘플은 말뭉치에 자주 등장하지 않는 희귀한 단어가 더 잘 뽑힐 수 있도록 설계하는데 이는 곧 너무 자주 등장하는 단어에 대한 확률을 높혀 계산에서 제외하는 방식으로 생각하면 된다. 디테일한 수식과 설명은 원래 reference를 참조하는 것이 좋을 것 같다.
Item2Vec - SGNS for item-based CF
이제 앞에서 본 알고리즘을 user가 만들어낸 item에 적용해보자. 이에 앞서 논문에서는 다음을 명시한다. user와 set of items에 관계에 대한 정보인데, 예를 들면 구매 확정이 아니라 장바구니에 담겼다는 정보로 이뤄진 데이터 셋일 수도 있다는 것이다. 이는 여러 set of items가 동일한 user에게 속할 수 있다는 것을 말한다.
장바구니 정보를 사용할 수 밖에 없다는 것으로 들리고, 또한 set of items라하면 집합으로 분류되어 구매 순서와 같은게 무시되는데 이는 고려하지 않는다고 한다. 즉, 동일한 set을 공유하는 항목이 사용자가 어떤 순서/시간에 생성하든 유사하게 고려되는 정적인 환경을 가정한다.
spatial information을 무시하기 때문에, 같은 set를 공유하는 한 쌍의 항목을 positive 표본으로 취급한다. 이는 설정된 크기에서 결정되는 window size를 의미한다.구체적으로, 주어진 항목 집합에 대해, Eq. (1)의 목표는 다음과 같다.
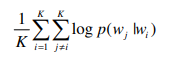
위의 식은 곧 단어에서 앞 단어, 앞앞 단어, 뒷 단어, 뒷뒷 단어를 쌍으로 고려했다면, 여기선 순서를 고려하지 않기 때문에 전체 항목들에 대해 쌍을 만들겠다는 의미이다. 이 때문인지 실행시키면서 랜덤으로 순서를 배정해서도 실험을 했는데 동일한 실험결과가 나왔다고 한다.
아무쪼록 임베딩이 끝나고 아이템간의 유사도는 코사인 유사도를 통해서 결정하였다. 코사인 유사도 말고 $u + v$ 또는 내적으로 구하였고, 때때로 좋은 성능을 보였다고 한다.
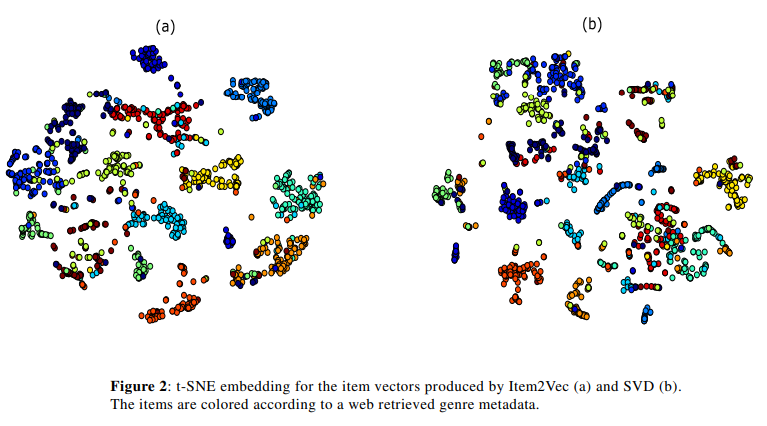
Figure 2는 기존의 SVD와의 임베딩을 비교한 결과이다. 아티스트를 장르에 따라 클러스터링할 것이다라는 가정(latent features)으로 나타낸 것이다. 항목들은 색깔별로 장르라는 메타데이터에 따라 구분된 것이다. (a)가 조금 더 분류가 잘 된 것 같다. 데이터는 music dataset을 사용했고 장르가 없어서 손으로 직접 다 검색해서 아티스트랑 장르를 기입했다.
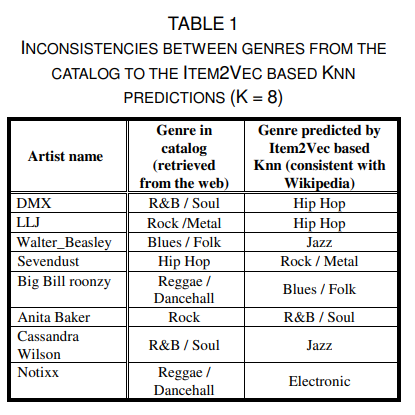
TABLE1은 위해 장르별 100대 인기 아티스트를 포함하는 하위 집합을 생성한 것이다.
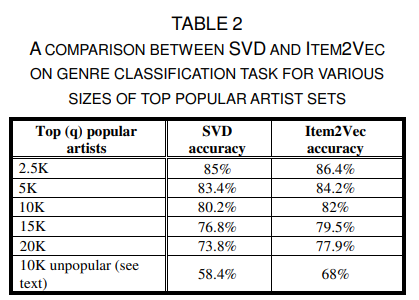
TABLE 2는 SVD랑 비교해서 성능이 좋다라는 것을 보여준다.
Item2Vec은 KNN 분류기를 사용해서도 잘못된 라벨링 찾아 이를 수정하는데 도움을 줄 수 있을 것이라 한다.
라벨이 없는 데이터 사용으로 인한 질적 평가가 불가피 하다. 하지만 SVD보다 관련 항목을 더 잘 나타낸다.
paper: https://arxiv.org/vc/arxiv/papers/1603/1603.04259v2.pdf
reference: Sentence Embeddings Using Korean Corpora
'Reading' 카테고리의 다른 글
| 럭키 드로우 (0) | 2022.06.19 |
|---|---|
| 돌이킬 수 없는 약속 (0) | 2020.07.13 |
| Matrix Factorization Techniques for Recommender Systems (0) | 2020.04.01 |
| A Hybrid Movie Recommender System Based on Neural Networks (0) | 2020.02.27 |
| Recommender systems survey(2) (0) | 2020.02.12 |



댓글