어쩌다 알게된 .. ~.~ 논문 Deep Clustering for Unsupervised Learning of Visual Features 리뷰.
본 논문에서는 주장하는 기여점은 크게 4가지라고 주장한다.
첫째, k-means와 같은 표준 클러스터링 알고리즘과 함께 작동하는 convnets의 end-to-end학습을 위한 최소한의 단계만을 필요로하는 새로운 USL(UnSupervised Learning) 방법이라는 것.
둘째, USL을 사용하는 많은 표준 transfer task에 대해 SOTA성능을 지닌다는 것.
셋째, 정해져있지 않은 이미지 분포에 대한 학습을 진행할 때, 이전 SOTA 보다 나은 성능을 지닌다는 것.
넷째, USL 피쳐 학습에서 현재 평가 프로토콜에 대한 토의를 함.
1. Introduction
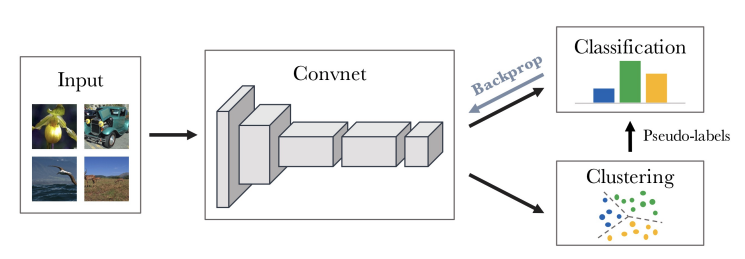
이 논문 같은 경우는 위에 보는 바와 같이 Semi-supervised learning(SSL)와 밀접한 연관이 있다. SSL은 라벨이 달린 학습셋 구축이 현실적으로 힘드니까 등장했다고 보면 되는데, 위 그림에서 Clustering 이후 Pseudo-labels가 그것이다. 라벨이 없는 데이터셋에 대해 unsupervised learning을 진행하고 class 개수만큼 clustering을 한다. 이 때, feature에 대해서 Centroid에 가까워지도록 하는 손실함수를 최소화하게끔 학습을 하는데, 이러한 작업으로 clustering한 클래스들이 Classification에 class에 할당될 수 있게 한다. 이 때 가정은 유사한 아이들끼리는 같은 class로 볼 수 있다는 가정인데, ref)2의 아티클을 참조하면 좋다!
3.1 Preliminaries
이 장에서는 기본적으로 분류기랑 그에 대한 손실함수에 대해 간략히 설명한다.
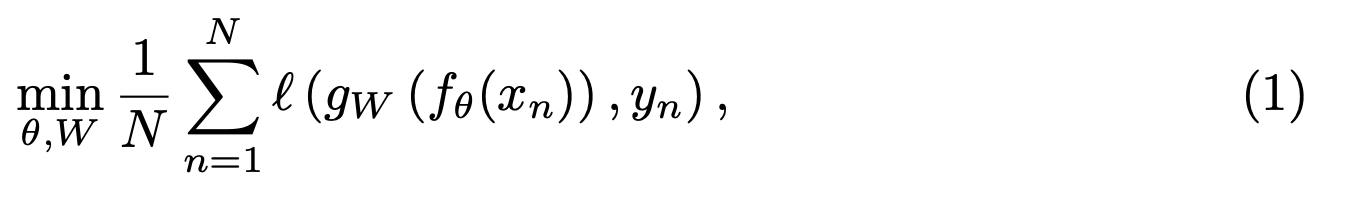
수식(1)에 대해 살펴보면, $f_{\theta}$는 Convnet에 대한 맵핑이고, $\theta$가 이에 해당하는 파라미터이다. $N$개의 이미지에서 학습 셋 $X=\{x_{1}, x_{2}, ... , x_{3} \}$ 이 주어질 때, $f_{\theta^{*}}$가 좋은 일반화 피쳐를 뽑기 위해서 이에 대한 파라미터 $\theta^{*}$를 찾는다고 보면 된다. feature부분은 $f_{\theta}(x_{n})$ 이고, $gW$ 분류기로 클래스를 분류한다.
$W$는 분류기에 파라미터이고, $\theta$는 위 (1)손실함수를 최적화하도록 함께 학습한다. $\ell$는 negative log-softmax 함수로도 알려진 multinomial logistic loss다.
3.2 Unsupervised Learning by clustering
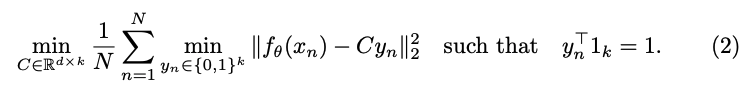
별다른 학습 없이 $\theta$가 가우시안 분포로 부터 샘플링되지 않을 때, $f_{\theta}$는 좋은 피쳐를 잘 못만든다. 하지만 전이학습 테스크로 넘어오면 랜덤한 feature에 대한 성능은 훨씬 높다. 랜덤 convnet이 좋은 성능을 내는 것은 input signal에 강한 우선순위를 부여하는 convnet 구조와 밀접하게 관련되어 있다. 그래서 본 논문의 아이디어는 이 weak signal을 이용해 convnet의 판별력을 부트스트랩 한다.
convnet의 output을 클러스터링하고, 수식(1)을 최적화하기 위해 "pseudo-labels"로써 후속 클러스터를 할당하는데 사용한다. 이러한 deep clustering은 반복적으로 피쳐를 학습하고, 그룹화 한다.
DeepCluster는 수식(2)를 사용해 "pseudo-labels"를 생성하기 위해 피쳐에 대한 클러스터링을 수행한다. 그리고 수식(1)에서 얻은 "pseudo-labels"를 예측함으로써 convnet의 파라미터를 업데이트한다.
수식(2)는 $f_{\theta}(x_{n}) - C_{y_{n}}$ 을 최소화하고자 하는 것이고, 의미는 k-means의 centroid와 feature들 사이의 차이가 적도록 하겠다는 의미이다.
요약하면! convnet에서 라벨을 모르는 입력에 대한 예측값을 뽑고, 이 예측값을 클러스터링한다는 소리다.
그런데 이러한 유형의 반복 절차는 다소 trivial한 솔루션인 경향이 있고, 여기서 발생하는 단점을 피하기 위한 몇가지 방법들을 소개한다.
3.3 Avoiding trivial solutions
trivial한 솔루션은 신경망으로 비지도학습하는 것에만 국한되지 않고, 라벨과 분류기를 공동으로 학습하는 것에도 중요하다.
Empty clusters: discriminative model은 decision boundary를 만들어 놓고, 모든 입력들을 하나의 클러스터에 할당하기 마련인데, 이 때 이슈는 비어있는 클러스터의 존재로부터 야기되고, convnet만큼 많이 linear model에서 발생한다. 흔한 트릭은 k-means 최적화하는 동안에 비어있는 클러스터에 자동적으로 재할당하도록 feature quantization을 사용하는 것이다.
비어있는 클러스터의 중심점으로 비어있지 않은 클러스터의 중심점을 랜덤으로 선택해 비어있는 클러스터의 중심점으로 할당한다. 그리고 비어있지 않은 두 클러스터에 속하는 포틴트를 두개의 클러스터에 재할당한다.
Trivial parametrization: 대다수의 이미지가 한 클러스터로 쏠리는 경우가 있을 것이다. 극단적인 경우에는 입력에 관계없이 한 클래스로만 출력할수도 있다. 이걸 피하기 위해 클래스나 pseudo-labels에 대한 균일한 분포를 기반으로하도록 샘플링을 실시한다. 식(1)에서 입력의 기여도에 대한 가중치를 부여하는 것과 같다.
6. Conslusion
비지도학습에 대한 확장가능한 클러스터링을 제안했다. convnet에서 생성된 feature를 클러스터링 하는 것과 pseudo-labels로 할당된 클러스터를 예측하면서 해당 가중치를 업데이트한다. 실험엔 ImageNet, YFCC100M을 사용했고 SOTA를 찍었다. 본 연구는 입력에 대해 가정이 거의 없고 많은 도메인 특화된 지식이 필요하지 않다. 👍
느낀점. 가성비 좋은 클러스터링. 😻
ref)
1. paper: https://arxiv.org/abs/1807.05520
Deep Clustering for Unsupervised Learning of Visual Features
Clustering is a class of unsupervised learning methods that has been extensively applied and studied in computer vision. Little work has been done to adapt it to the end-to-end training of visual features on large scale datasets. In this work, we present D
arxiv.org
2. EST기술블로그: https://blog.est.ai/2020/11/ssl/
Semi-supervised learning 방법론 소개
머신러닝의 학습 방법 중 하나인 준지도학습(semi-supervised learning, SSL) 관련 글
blog.est.ai
'Reading' 카테고리의 다른 글
| 럭키 드로우 (0) | 2022.06.19 |
|---|---|
| 돌이킬 수 없는 약속 (0) | 2020.07.13 |
| Item2Vec: Neural Item Embedding for Collaborative Filtering (0) | 2020.04.15 |
| Matrix Factorization Techniques for Recommender Systems (0) | 2020.04.01 |
| A Hybrid Movie Recommender System Based on Neural Networks (0) | 2020.02.27 |



댓글